供南开大学计算机学院和网络空间安全学院期末复习使用
免责声明:本人水平有限,笔记难免有错误,请理性使用,切莫完全相信本笔记的所有内容。
分值分配:课上随堂测试考核(10%)、研讨内容(10%)、实验内容考核(40%)和期末考试(40%)
期末考试:30道选择题(每小题2分)4道简答题(每小题5分)2道解答题(每小题10分)
第三章 搜索求解
知识点
一些名词
状态 对智能体和环境当前情形的描述。例如,在最短路径问题中,城市可作为状态。将原问题对应的状态称为初始状态 动作 从当前时刻所处状态转移到下一时刻所处状态所进行操作。一般而言这些操作都是离散的
状态转移 对智能体选择了一个动作之后,其所处状态的相应变化 路径/代价 一个状态序列。该状态序列被一系列操作所连接。如从
到 所形成的路径 目标测试 评估当前状态是否为目标状态
搜索算法
集合

但是并不是所有的后继节点都值得被探索,所以我们需要再探索的过程中进行剪枝

上图就是图搜索,要求不能出现环
启发式搜索
分为贪婪最佳优先搜索和
我们有两个函数来辅助我们进行搜索
| 辅助信息 | 所求解问题之外、与所求解 问题相关的特定信息或知识。 | |
|---|---|---|
| 评价函数 |
从当前节点n出发,根据评价函数来选择后续结点。 | 下一个结点是谁? |
| 启发函数 |
从结点n到目标结点之间所形成路径的最小代价值,这里用两点之间的直线距离。 | 完成任务还需要多少代价? |
在贪婪最佳优先搜索中,我们将评价函数定为启发函数,启发函数是由任意一个城市与终点城市
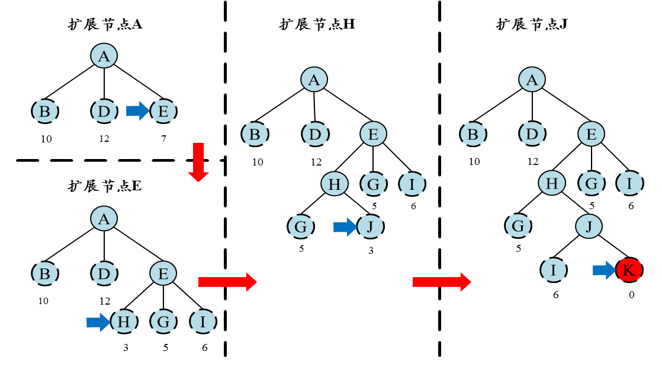
在A*搜索中,我们的评价函数是启发函数+开销函数
评价函数就是,起始结点到结点
对抗搜索
也称为博弈搜索,就是在竞争的过程中,一方尽可能最大化利益,另一方尽可能的最小化利益

minimax搜索
就是双方都往不同的结果靠拢,而且必须是零和博弈,优点是双方都尽力的情况下,会获得最好的结果,缺点是时间复杂度太高,返回结果太慢,因此我们选择使用

给一个例子说明:
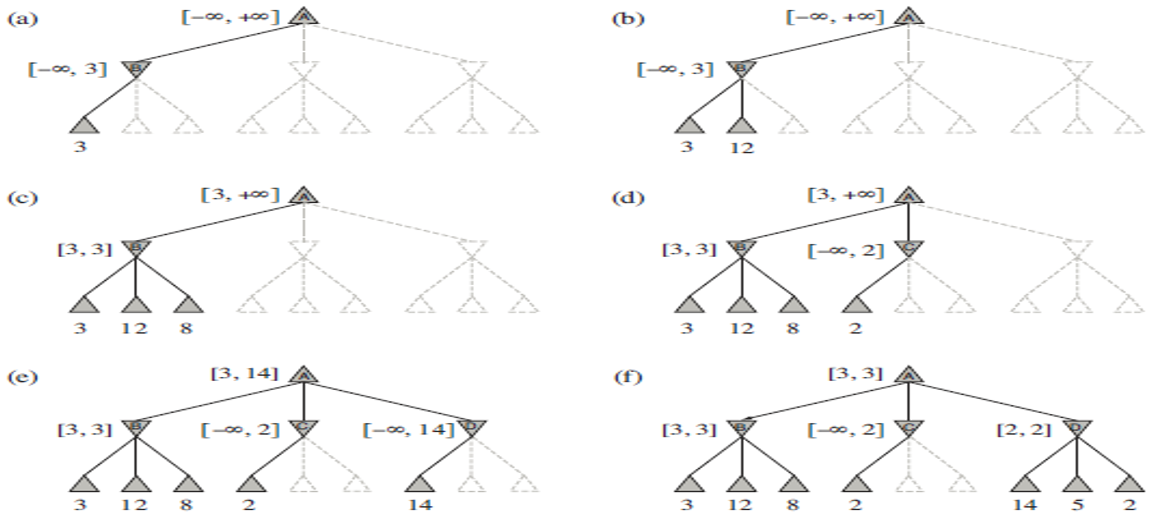

修改方式:
层改 , 层改 当
的时候就剪枝(注意等于号) 先传递到左子树,再返回父节点,然后再传递到右子树,再回溯就可以了
修改值的方法:
- 当在
层进行修改的时候,是取自己,下一层的 和 的最大值 - 当在
层进行修改的时候,是取自己,下一层的 和 的最小值
具体例子:见课本图3.16和图3.17
书本习题9(1):
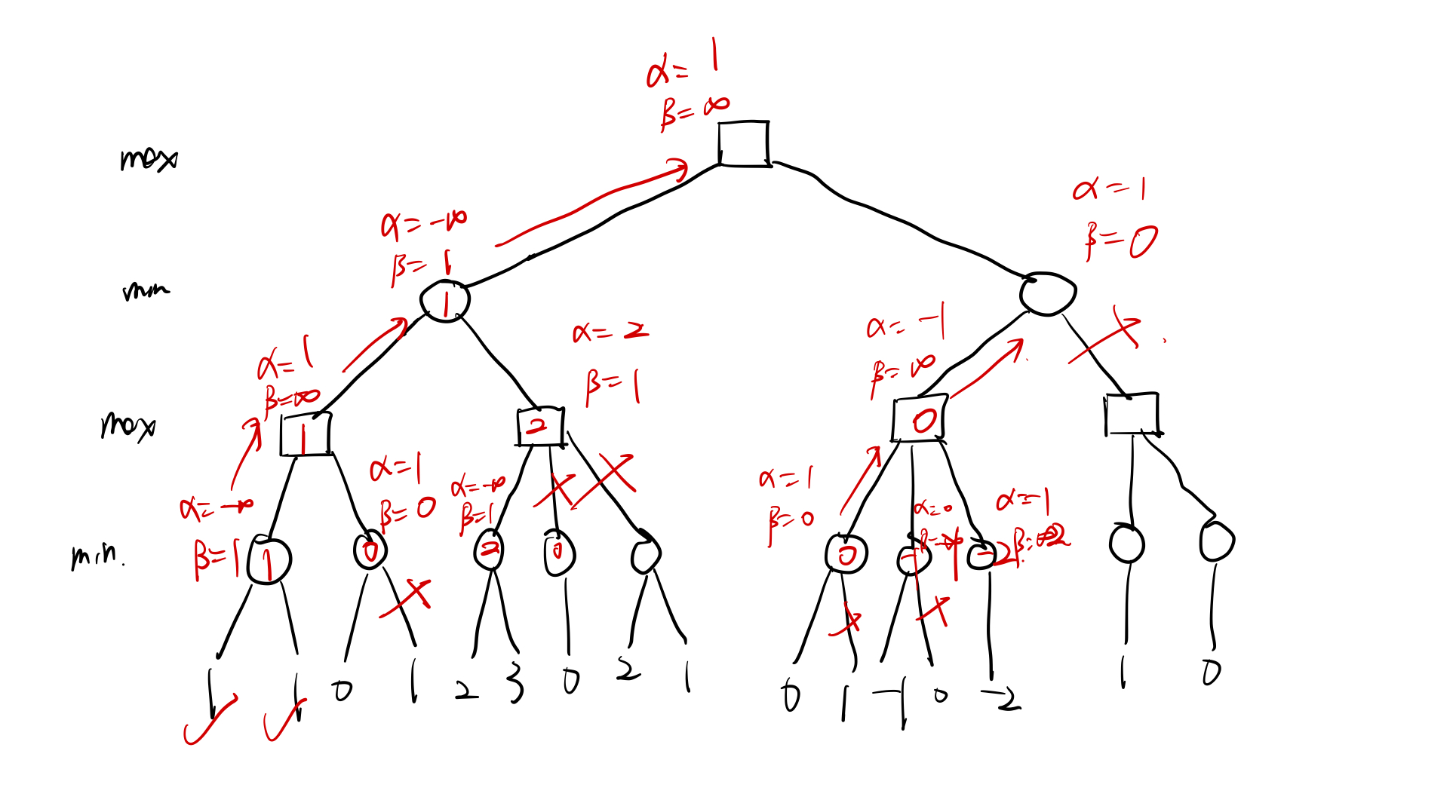
学习网址:最清晰易懂的MinMax算法和Alpha-Beta剪枝详解
剪枝本身不影响算法输出结果 节点先后次序会影响剪枝效率
如果节点次序“恰到好处”,
蒙特卡洛树搜索
悔值函数:
C是一个平衡因子,来决定算法中选择偏重探索还是利用
蒙特卡洛树的具体流程:分为四个步骤,分别是选择,扩展,模拟,反向传播
- 选择: 从根节点
开始,递归选择子节点,直至到达叶节点或到达具有还未被扩展过的子节点的节点 。具体来说,通常用 ( ,上限置信区间)选择最具“潜力”的后续节点 - 扩展 :如果
不是一个终止节点,则随机创建其后的一个未被访问节点,选择该节点作为后续子节点 。 - 模拟:从节点
出发,对游戏进行模拟,直到博弈游戏结束。 - 反向传播:用模拟所得结果来回溯更新导致这个结果的每个节点中获胜次数和访问次数。
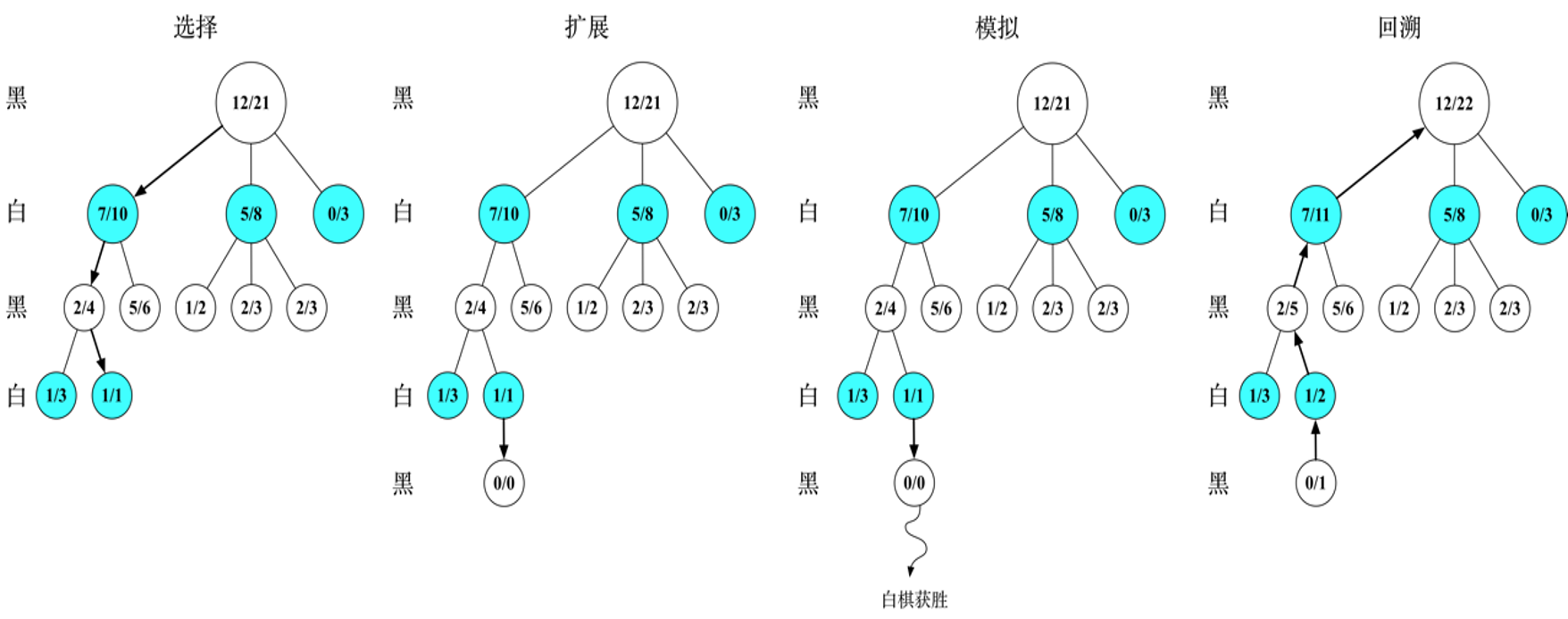
记录
假设黑棋先手,则:
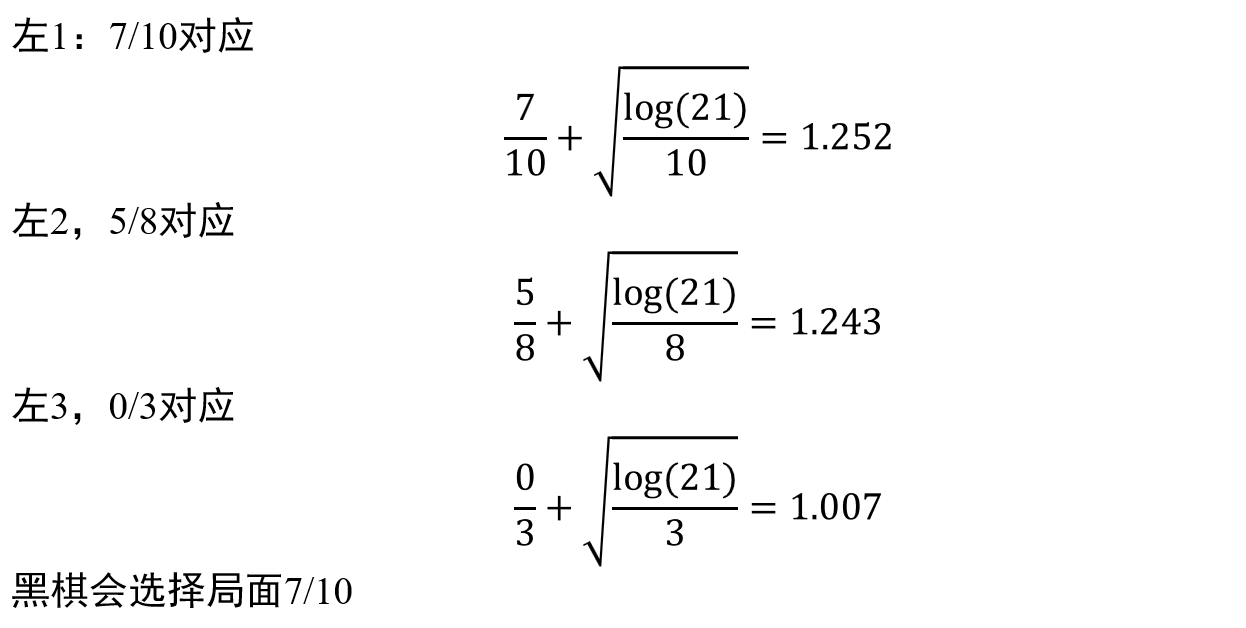
然后就是白棋落子,注意公式的第一部分需要用
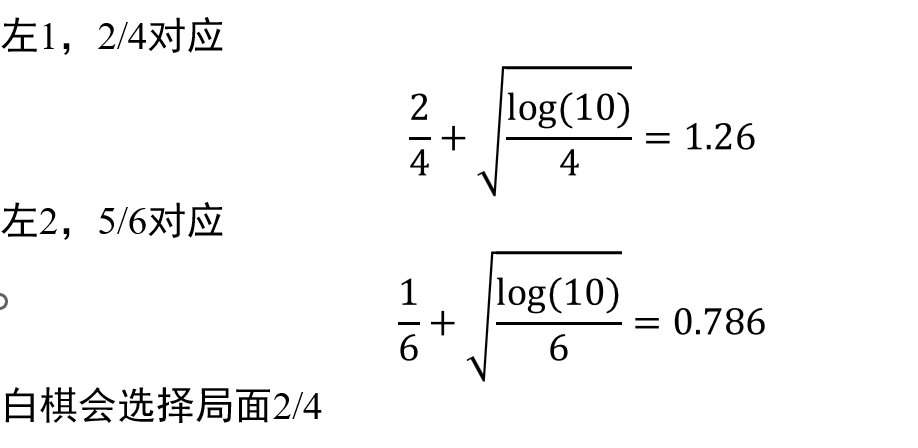
就这样一直往下遍历,直到最底部,黑棋选择
随机扩展一个新节点,初始化为
这样我们就完成了蒙特卡洛树的四个步骤:选择,扩展,模拟,反向传播