供南开大学计算机学院和网络空间安全学院期末复习使用
免责声明:本人水平有限,笔记难免有错误,请理性使用,切莫完全相信本笔记的所有内容。
分值分配:课上随堂测试考核(10%)、研讨内容(10%)、实验内容考核(40%)和期末考试(40%)
期末考试:30道选择题(每小题2分)4道简答题(每小题5分)2道解答题(每小题10分)
第七章 强化学习
知识点
强化学习问题定义
强化学习可以学习到最大化收益的模式
强化学习的一些概念:
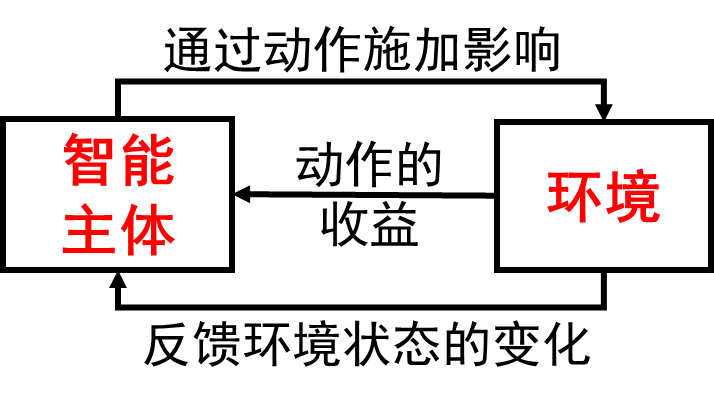
智能主体:按照某种策略(
- 状态指的是智能主体对环境的一种解释
- 动作反映了智能主体对环境主观能动的影响,动作带来的收益称为奖励(
)
环境:系统中除去智能主体以外的部分,向智能主体反馈状态和奖励,按照一定的规律发生变化
强化学习&监督学习&无监督学习
| 有监督学习 | 无监督学习 | 强化学习 | |
|---|---|---|---|
| 学习依据 | 基于监督信息 | 基于对数据结构的假设 | 基于评价( |
| 数据来源 | 一次性给定 | 一次性给定 | 在交互中产生 |
| 决策过程 | 单步( |
无 | 序列( |
| 学习目标 | 样本到语义标签的映射 | 同一类数据的分布模式 | 选择能够获取最大收益的状态到动作的映射 |
为了介绍接下来的内容,我们基于一个简单的例子来介绍相关的定义。
在一个
的网格中,假设有一个机器人位于 ,试图从 这一初始位置向 这一目标位置移动,假设机器人每一步只能向上或向右移动一个方格,到达目标位置 则会获得奖励且游戏终止,机器人在移动过程中如果越出方格则会被惩罚,并且游戏终止。那么,如何学习一种策略能够帮助机器人从 走到 ?
在这个问题中,智能主体为迷宫机器人,环境是
在这个例子中,我们可以采取随机过程机器人与环境之间的交互。
一个随机过程是一列随时间变化的随机变量。当时间是离散量时,一个随机过程可以表示为
定义离散马尔可夫过程
我们将到达
于是,我们得到了马尔可夫奖励过程,其形式化的定义为
我们引入动作集合
马尔可夫过程中产生的状态序列称为轨迹,轨迹的长度可以是无限的,也可以是有终止状态的。有终止状态的问题叫做分段的,否则叫做持续的。分段问题中,一个从初始状态到终止状态的完整轨迹称为一个片段或回合。
接下来我们对强化问题下定义。首先定义如下函数
- 价值函数
,其中 ,即在第 步状态为 时,按照策略 行动后在未来所获得的反馈值的数学期望 - 动作-价值函数
,其中 表示在第 步状态为 时,按照策略 采取动作 后,在未来所获得的反馈值的期望
至此,强化学习转化为一个策略问题:寻找一个最优策略
最后我们介绍贝尔曼方程,也称动态规划方程。
价值函数的贝尔曼方程
动作-价值函数的贝尔曼方程
价值函数的贝尔曼方程描述了当前状态价值函数和其后续状态价值函数之间的关系,即当前状态价值函数等于瞬时奖励的期望加上后续状态的(折扣)价值函数的期望。而动作-价值函数的贝尔曼方程描述了当前动作-价值函数和其后续动作-价值函数之间的关系,即当前状态下的动作-价值函数等于瞬时奖励的期望加上后续状态的(折扣)动作-价值函数的期望。
基于价值的强化学习
策略优化定理:给定任意状态
下面介绍在状态集合有限前提下三种常见的策略评估方法,它们分别是基于动态规划的方法、基于蒙特卡洛采样的方法和时序差分法。
基于动态规划的方法:使用迭代的方法求解贝尔曼方程组
缺点:
- 智能主体需要实现知道状态转移概率
- 无法处理状态集合大小无线的情况
蒙特卡洛采样:选择不同的起始状态,按照当前策略
采样若干轨迹,记他们的集合为 ,枚举 。计算D中s每次出现时对应的反馈 , 优点:
- 不必知道状态转移概率
- 容易扩展到无限状态集合的问题中
缺点:
- 状态集合比较大时,一个状态在轨迹可能非常稀疏,不利于估计期望
- 在实际问题中,最终反馈需要在终止状态才能知晓,导致反馈周期较长
时序差分法:通过采样
和 来估计 的取值 ,并以 作为权重接受新的估计值,即把价值函数更新为
- 初始化
为初始状态 - 比较动作-价值函数最优的动作,设为
- 执行动作
,观察奖励 和下一个状态 - 更新
- 更新状态
,重复执行步骤 到 ,直到 是终止状态(一个片段) - 重复执行步骤
到 ,直到 收敛
这样的
注意这时采样时策略为
将
- 能够用有限的参数刻画无限的状态
- 由于回归函数的连续性,没有探索过的状态也可通过周围的状态来估计