第八章 漏洞挖掘技术
程序切片技术
概述
程序切片旨在从程序中提取满足一定约束条件的代码片段
- 对指定变量施加影响的代码指令
- 或者指定变量所影响的代码片段
定义:给定一个切片准则 C=(N, V),其中N表示程序P中的指令,V表示变量集,程序P关于C的映射即为程序切片。换句话说,一个程序切片是由程序中的一些语句和判定表达式组成的集合。
分类:
- 前向切片,计算方向与程序相同
- 后向切片
C=(4, z)指的就是,从C代码的第四行开始,做前向切片,只关注我们的z变量
控制依赖图(CFG)
是一个过程或程序的抽象表现,代表了一个程序执行过程中会遍历到的所有路径
一个程序的控制流图CFG可以表示为一个四元组,形如G = (V, E, s, e),其中V表示变量的集合,E表示表示边的集合,s表示控制流图的入口,e表示控制流图的出口
程序中的每一条指令都映射为CFG上的一个结点,具有控制依赖关系的结点之间用一条边连接
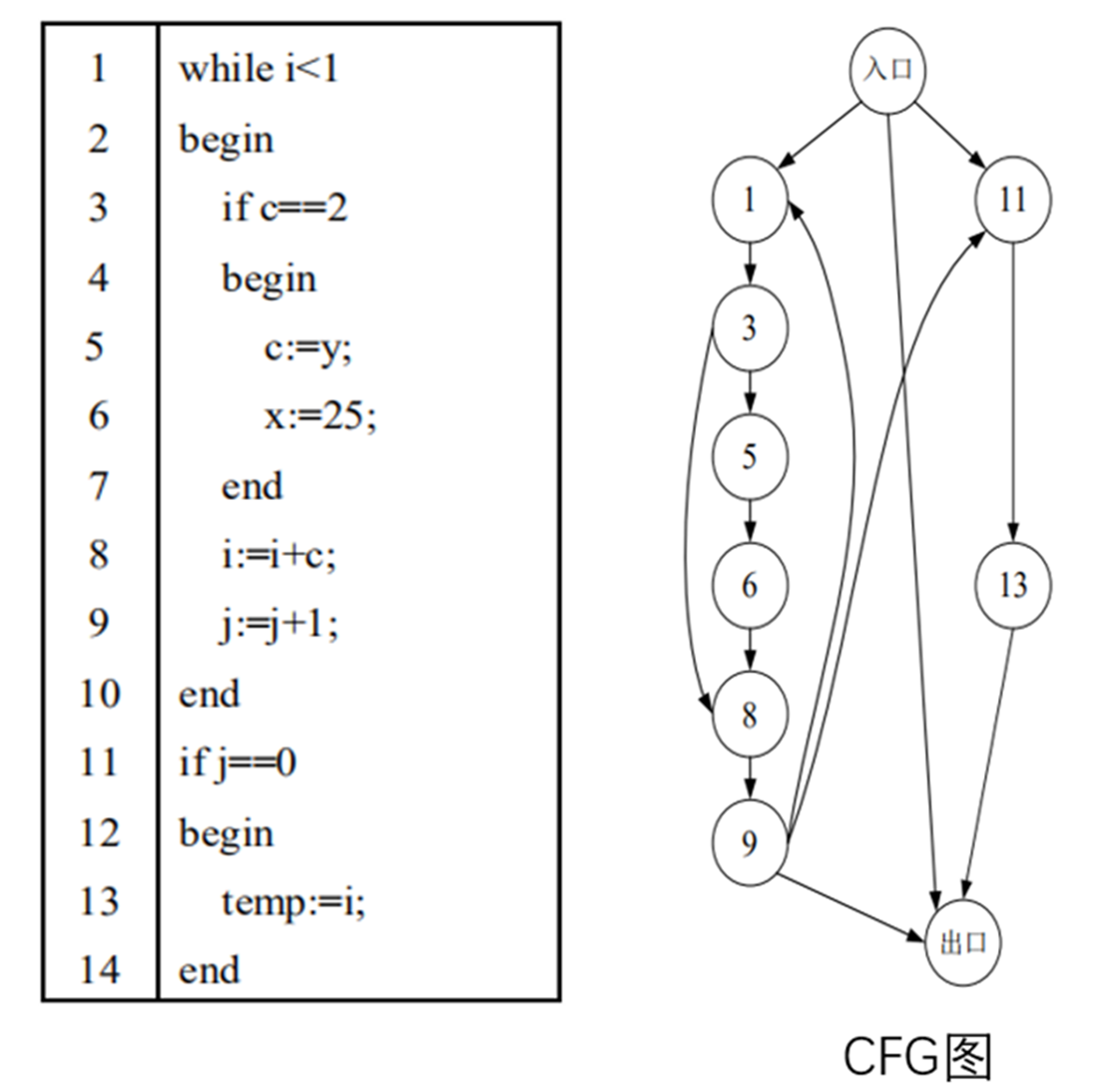
比如说我们的356语句受到1的影响,那么我们就将其标在1的后面
控制依赖的来源:程序上下文;控制指令
程序依赖图(PDG)
程序依赖图(Program Dependence Graph,PDG)可以表示为一个五元组,形如G = (V, DDE, CDE, s, e),其中V表示变量的集合,DDE表示数据依赖边的集合,CDE表示控制依赖边的集合,每条边连接了图中的两个结点,程序中的每一条指令都映射为PDG上的一个结点。s表示程序依赖图的入口结点,e表示程序依赖图的出口结点
- 控制依赖:表示两个基本块在程序流程上存在的依赖关系。
- 数据依赖:表示程序中引用某变量的基本块(或者语句)对定义该变量的基本块的依赖,即是一种“定义-引用”依赖关系
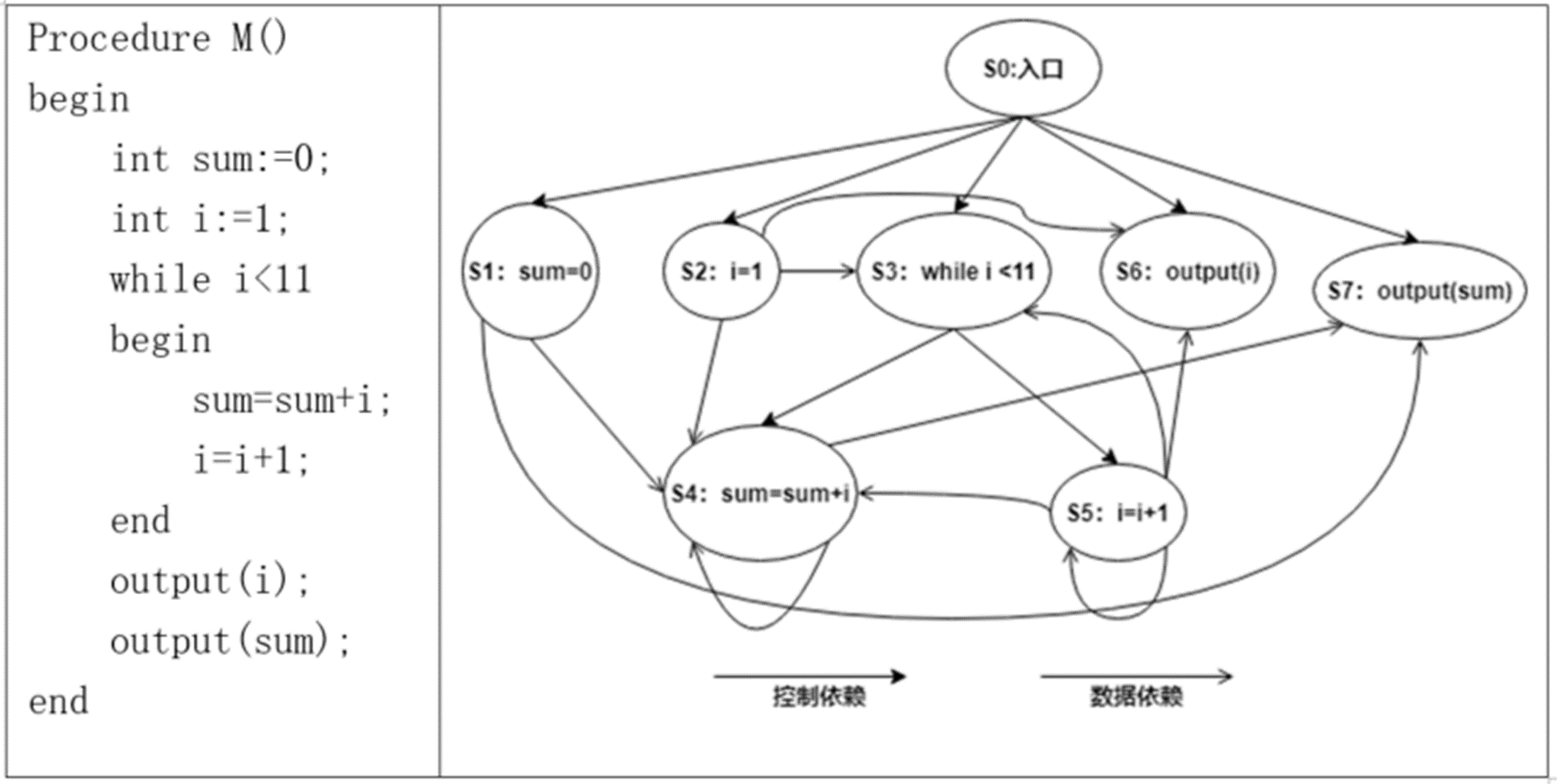
我们将控制依赖用粗的箭头表示,将数据依赖用细的箭头表示
举个例子:S4语句,sum的值必定受到S1的影响,所以是数据依赖;还收到S5中的i的数据依赖影响;还收到自己的控制依赖影响,因此是三个箭头
系统依赖图(SDG)
系统依赖图(System Dependence Graph,SDG):可以表示为一个七元组,形如G = (V,DDE, CDE, CE, TDE, s, e),其中V变量的集合,DDE表示数据依赖边的集合,CDE表示控制依赖边的集合,CE表示函数调用边,TDE表示参数传递造成的传递依赖边的集合,结点s表示系统依赖图的入口结点,结点e表示系统依赖图的出口结点。
SDG在PDG的基础上进行了扩充,系统依赖图中加入了对函数调用的处理
程序切片方法
定义
包含两个要素,即
- 切片目标变量(如变量z)
- 开始切片的代码位置(如z所在的代码位置:第12行)
程序P的切片准则是二元组<n,V>
- n是程序中一条语句的编号
- V是切片所关注的变量集合
- 该集合是P中变量的一个子集
程序切片通常包括3个步骤:程序依赖关系提取、切片规则制定和切片生成。
- 程序依赖关系提取主要是从程序中提取各类消息,包括控制流和数据流信息,形成程序依赖图。
- 切片规则制定主要是依据具体的程序分析需求设计切片准则。
- 切片生成则主要是依据前述的切片准则选择相应的程序切片方法,然后对第一步中提取的依赖关系进行分析处理,从而生成程序切片。
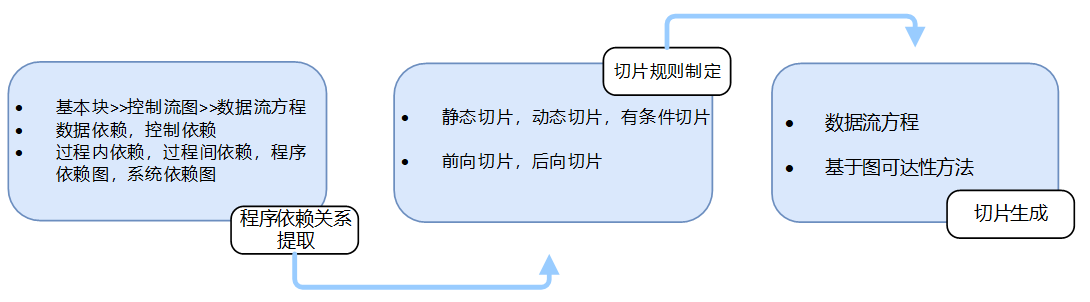
图可达算法
切片过程
- 输入:结点Node
- 输出:结点集VisitedNodes
步骤
- 步骤1:判断Node是否在结点集VisitedNodes,结果为是,则return;结果为否,则进入步骤2;
- 步骤2:将Node添加到VisitedNodes中;
- 步骤3:在程序依赖图中遍历Node依赖的结点,得到结点集Pred;
- 步骤4:对于每一个pred∈Pred,迭代调用PDGSlice(pred)
动态程序切片
动态切片需要考虑程序的特定输入,切片准则是一个三元组(N, V, I),其中 N 是指令集合,V 是变量集合,I 是输入集合
我们输入C1=(13, a, x=1, y=1,z=0),这样就是说明了z的值,这样我们就可以将一些没有用的代码给剪掉
动态切片就是跟我们的未知数的取值有关,是静态切片的子集
条件切片
条件切片的切片准则也是一个三元组,形为C = (N, V, FV),其中 N 和 V 的含义同静态准则相同,FV是 V 中变量的逻辑约束
静态切片和动态切片可以看做条件切片的两个特例:当FV中的约束条件为空时,得到的切片是静态切片;当FV中的约束固定为某一特定条件时,得到的切片是动态切片
程序插桩技术
插桩就是在代码中插入一段我们自定义的代码,它的目的在于通过我们插入程序中的自定义的代码,得到期望得到的信息,比如程序的控制流和数据流信息,以此来实现测试或者其他目的
分类:
- 源代码插桩
- 静态二进制插桩
- 动态二进制插桩
| 插桩粒度 | API | 执行时机 |
|---|---|---|
| 指令级插桩(instruction) | INS_AddInstrumentFunction | 执行一条新指令 |
| 轨迹级插桩(trace) | TRACE_AddInstrumentFunction | 执行一个新trace |
| 镜像级插桩(image) | IMG_AddInstrumentFunction | 加载新镜像时 |
| 函数级插桩(routine) | RTN_AddInstrumentFunction | 执行一个新函数时 |
具体见实验8
消息Hook技术
消息Hook就是一个Windows消息的拦截机制,可以拦截单个进程的消息(线程钩子),也可以拦截所有进程的消息(系统钩子),也可以对拦截的消息进行自定义的处理:
- 如果对于同一事件(如鼠标消息)既安装了线程钩子又安装了系统钩子,那么系统会自动先调用线程钩子,然后调用系统钩子。
- 对同一事件消息可安装多个钩子处理过程,这些钩子处理过程形成了钩子链,后加入的有优先控制权
官方函数SetWindowsHookEx用于设置消息Hook
1 | HHOOK SetWindowsHookEx( |
DLL注入技术是向一个正在运行的进程插入自有DLL的过程。DLL注入的目的是将代码放进另一个进程的地址空间中
在Windows中,利用SetWindowsHookEx函数创建钩子(Hooks)可以实现DLL注入。设计实验如下:
- 编制键盘消息的Hook函数—KeyHook.dll中的KeyboardProc函数
- 通过SetWindowsHookEx创建键盘消息钩子实现DLL注入(执行DLL内部代码)
DLL基本格式:
导入函数
1 | BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD dwReason, LPVOID lpvReserved){ |
导出函数
1 |
|
API Hook技术
API HOOK的基本方法就是通过hook“接触”到需要修改的API函数入口点,改变它的地址指向新的自定义的函数
分类:
- IAT Hook:将输入函数地址表IAT内部的API地址更改为Hook函数地址
- 代码Hook:系统库(*.dll)映射到进程内存时,从中查找API的实际地址,并直接修改代码
- EAT Hook
符号执行基本原理
程序执行状态
符号执行具体执行时,程序状态中通常包括:程序变量的具体值、程序指令计数和路径约束条件pc(path constraint)
pc是符号执行过程中对路径上条件分支走向的选择情况,根据状态中的pc变量就可以确定一次符号执行的完整路径。pc初始值为true
遇到条件分支就是左右分叉,运算语句就是代入未知数
符号传播
建立符号变量传播的关系,并且更新映射的关系——将对应内存地址的数据进行变化
1 | int x; |
| 符号量的内存地址 | 符号值 |
|---|---|
| add_x | X |
| add_y | X*3 |
| add_z | X*3 + 5 |
符号执行树
程序的所有执行路径可以表示为树,叫做执行树。符号执行过程也是对执行树进行遍历的过程
1 | 1 void foobar(int a,int b){ |
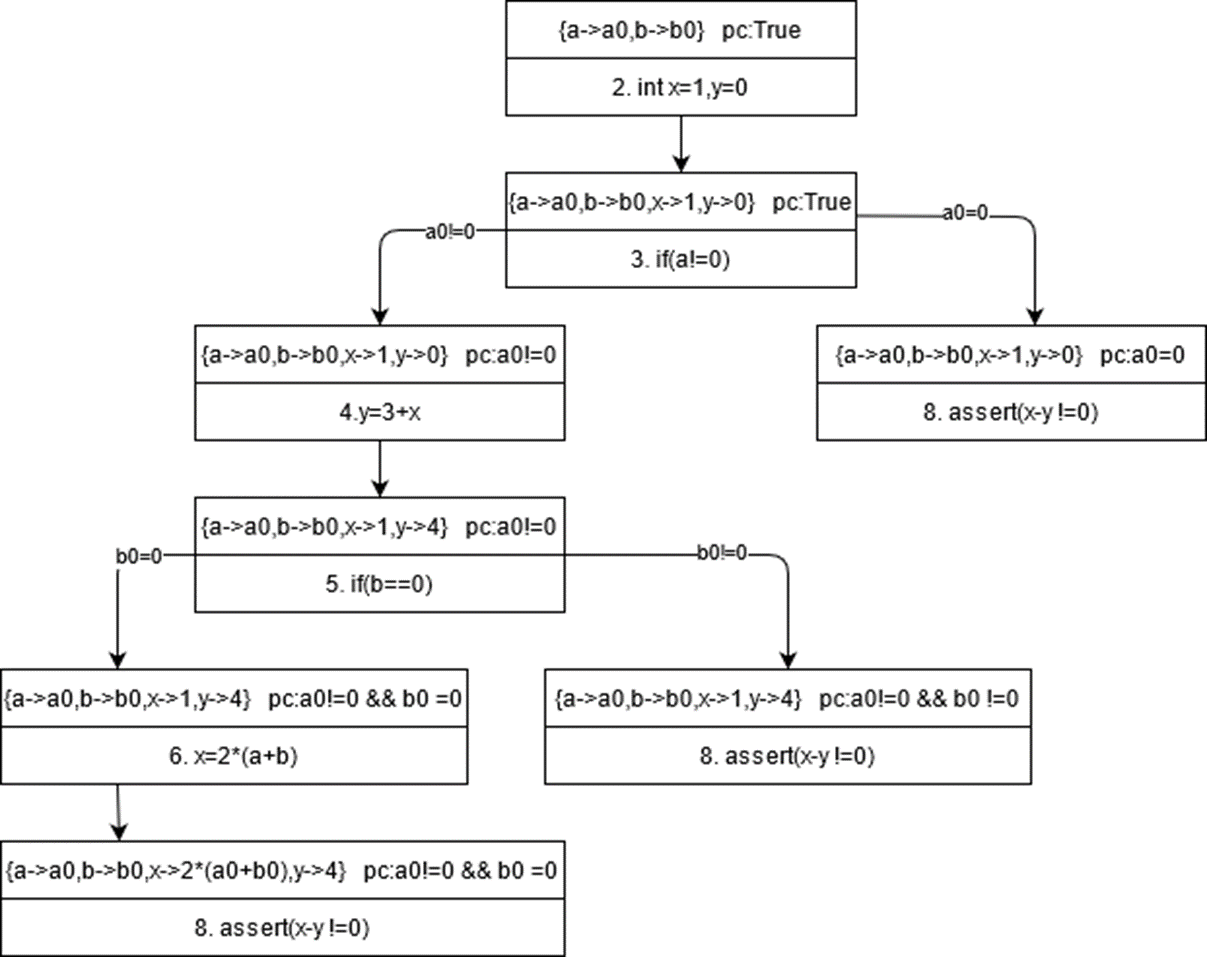
结合assert的约束x-y!=0就可以进行求解出触发约束的输入
约束求解
类似于解方程,利用我们的符号执行中得到的式子来进行计算
- SAT问题(The Satisfiability Problem,可满足性问题)
- SMT(Satisfiability Module Theories,可满足性模理论)
符号执行方法分类
- 静态符号执行本身不会实际执行程序,通过解析程序和符号值模拟执行,有代价小、效率高的优点,但是存在路径爆炸、误报高的情况
- 动态符号执行也称为混合符号执行,它的基本思想是:以具体的数值作为输入执行程序代码,在程序实际执行路径的基础上,用符号执行技术对路径进行分析,提取路径的约束表达式,根据路径搜索策略(深度、广度)对约束表达式进行变形,求解变形后的表达式并生成新的测试用例,不断迭代上面的过程,直到完全遍历程序的所有执行路径。
- 选择性符号执行可以对程序员感兴趣的部分进行符号执行,其它的部分使用真实值执行,在特定任务环境下可以进一步提升执行效率
Z3约束求解器
——SMT问题的开源约束求解器,就是自动解方程组
一般使用的方法:
- Solver():创建一个通用求解器,创建后可以添加约束条件,进行下一步的求解。
- add():添加约束条件,通常在solver()命令之后。
- check():通常用来判断在添加完约束条件后,来检测解的情况,有解的时候会回显sat,无解的时候会回显unsat。
- model():在存在解的时候,该函数会将每个限制条件所对应的解集取交集,进而得出正解
Angr应用示例
见实验
变量符号化——动态符号执行——获取路径约束条件——约束求解
污点分析基本原理
- 污点分析标记程序中的数据(外部输入数据或者内部数据)为污点,通过对带污点数据的传播分析来达到保护数据完整性和保密性的目的
- 如果信息从被标记的污点数据传播给未标记的数据,那么需要将未标记的标记为污点数据;如果被标记的污点数据传递到重要数据区域或者信息泄露点,那就意味着信息流策略被违反
污点分析可以抽象成一个三元组(sources,sinks,sanitizers)的形式:
- source即污点源,代表直接引入不受信任的数据或者机密数据到系统中;
- sink即污点汇聚点,代表直接产生安全敏感操作(违反数据完整性)或者泄露隐私数据到外界(违反数据保密性);
- sanitizer即无害处理,代表通过数据加密或者移除危害操作等手段使数据传播不再对软件系统的信息安全产生危害。
污点分析就是分析程序中由污点源引入的数据是否能够不经无害处理,而直接传播到污点汇聚点。如果不能,说明系统是信息流安全的;否则,说明系统产生了隐私数据泄露或危险数据操作等安全问题
识别污点源和污点汇聚点是污点分析的前提
- 使用启发式的策略进行标记,例如把来自程序外部输入的数据统称为“污点”数据,保守地认为这些数据有可能包含恶意的攻击数据;
- 根据具体应用程序调用的API或者重要的数据类型,手工标记源和汇聚;
- 使用统计或机器学习技术自动地识别和标记污点源及汇聚点。
分类:显式流分析和隐式流分析
- 显式流分析:分析污点标记如何随程序中变量之间的数据依赖关系传播。
- 隐式流分析:分析污点标记如何随程序中变量之间的控制依赖关系传播,也就是分析污点标记如何从条件指令传播到其所控制的语句
隐式流的两个问题:
- 欠污染:由于对隐式流污点传播处理不当导致本应被标记的变量没有被标记的问题称为欠污染(under-taint)问题。
- 过污染:由于污点标记的数量过多而导致污点变量大量扩散的问题称为过污染(over-taint)问题。
无害处理:
- 常数赋值是最直观的无害处理的方式;
- 加密处理、程序验证等在一定程度上,可以认为是无害处理。
污点分析方法
显式流分析
静态分析:在不运行且不修改代码的前提下,通过分析程序变量间的数据依赖关系来检测数据能否从污点源传播到污点汇聚点
动态分析:在程序运行过程中,通过实时监控程序的污点数据在系统程序中的传播来检测数据能否从污点源传播到污点汇聚点。
隐式流分析
静态隐式流分析:需要分析每一个分支控制条件是否需要传播污点标记。路径敏感的数据流分析往往会产生路径爆炸问题,导致开销难以接受
动态隐式流分析:
- 如何确定污点控制条件下需要标记的语句的范围?动态执行轨迹并不能反映出被执行的指令之间的控制依赖关系
- 由于部分泄漏导致的漏报如何解决?指污点信息通过动态未执行部分进行传播并泄漏
- 如何选择合适的污点标记分支进行污点传播?鉴于单纯地将所有包含污点标记的分支进行传播会导致过污染的情况