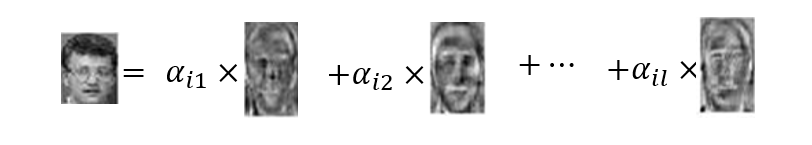供南开大学计算机学院和网络空间安全学院期末复习使用
免责声明:本人水平有限,笔记难免有错误,请理性使用,切莫完全相信本笔记的所有内容。
分值分配:课上随堂测试考核(10%)、研讨内容(10%)、实验内容考核(40%)和期末考试(40%)
期末考试:30道选择题(每小题2分)4道简答题(每小题5分)2道解答题(每小题10分)
第八章 博弈
知识点
博弈相关概念
玩家 (
- 某个玩家可采纳策略的全体组合形成了策略集 (
) - 所有玩家各自采取行动后形成的状态被称为局势 (
) - 混合策略 (
): 玩家可通过一定概率来选择若干个不同的策略 - 纯策略 (
): 玩家每次行动都选择某个确定的策略
收益 (
- 混合策略意义下的收益应为期望收益 (
)
规则 (
囚徒困境:警方逮捕了共同犯罪的甲和乙,但没有掌握充分证据,将他们分开审讯,并告诉他们如下事实:
- 若一人认罪并指证对方,而另一方保持沉默,则此人会被当即释放,沉默者会被判监禁
年 - 若两人都沉默,则根据已有的犯罪证据两人各判半年
- 若两人都认罪并相互指证,则两人各判
年
在囚徒困境中,最有可能的判决就是两个人都指认对方,都获得五年的监禁
| (甲,乙)收益 | 乙沉默 (合作) | 乙认罪 (背叛) |
|---|---|---|
| 甲沉默 (合作) | ||
| 甲认罪 (背叛) |
最优解为两人同时沉默;但是两人实际倾向于选择同时认罪 (均衡解)
博弈的分类:
- 合作博弈与非合作博弈
- 静态博弈和动态博弈
- 完全信息博弈与不完全信息博弈
博弈的稳定局势即为纳什均衡 (
任何玩家单独改变策略都不会得到好处,也就是说当所有其他人都不改变策略时,没有人会改变自己的策略
纳什均衡的本质就是不后悔
遗憾最小化算法
若干定义
- 玩家
所采用的策略为 ,一个策略组 包含所有玩家的策略, - 玩家
的策略空间用 表示 表示 中除了 之外的策略
- 玩家
- 玩家
在给定策略 下的期望收益为:
策略选择
根据过去博弈中的遗憾程度来决定动作选择的方法
玩家
遗憾最小化例子:见
:石头剪刀布